Editor’s note: Leeza Slessareva is a statistician based in Mountain View, Calif.
Statistical testing is a standard practice in market research, with statistically significant findings routinely used to draw conclusions and guide business decisions. However, not all statistically significant results are meaningful. Statistical significance is guaranteed, given a large enough sample. Statistical non-significance does not necessarily mean “unimportant” as it may be an artifact of the small sample size. Thus, exclusive focus on statistical testing can lead to incorrect conclusions and poorly-informed business decisions.
As an illustration consider two companies that are testing if consumers’ interest in a new product is different across geographic regions. Company A has ample funding and is able to conduct a large-scale study. Company B has very limited funding and thus conducts a similar yet small-scale study. As a result, Company A obtains statistically significant differences across regions, while Company B does not. Based on the statistically significant findings, Company A concludes that there are important differences in consumer interest and develops and launches regionally-specific products accordingly. Company B, on the other hand, concludes that there are no important regional variations in interest and launches the same product across regions.
Which company has made the right business decision? Unfortunately, statistical testing alone does not provide us the answer. What is needed is a way of knowing if the differences both companies found across regions are important and meaningful to business (and not just statistically significant). This is where the concepts of effect size and power are vital.
Magnitude of the difference
The effect size provides information on the magnitude of the difference between conditions. One straightforward way of obtaining an effect size is to compare the average of one condition to the average of another condition. For example, the implications are clear when we know that one advertisement results on average in 10 percent more sales than the other advertisement. However, the interpretation of the results is not always so straightforward. Consider a study with the goal of comparing how two products are liked by consumers. The study uses a 10-point scale, where 0 indicates extreme disliking and 10 indicates extreme liking. The results from the study show that one product is rated on average a 6 and the other product is rated on average a 7. Is this one-point difference in liking between the two products small or large and what is the impact of this difference on business?
Effect size indices go beyond comparing averages of different conditions. Many effect sizes are not dependent on a scale used in a study and thus results across studies using different scales can be compared. Effect sizes can usually be expressed in percentages from 0 percent to 100 percent, with larger values indicating a more robust difference that is likely to have a substantial impact on business. Past research as well as linking effect size information with financial info (e.g., sales) will allow you to determine what effect size can be expected and the impact it will have on business.
Power is important
The focus of studies is usually on finding a significant difference, yet power is usually not considered. Power is very important as it is an indication of the probability of a study detecting a significant difference between conditions when the difference actually exists. Incorrectly concluding that different conditions (e.g., advertisements, products, regions) produce similar outcomes can be costly for business. Power ranges from 0 to 1, with values close to 1 indicating stronger power. Power is directly related to sample size, with larger sample size leading to higher power. As a rule of thumb, it is advisable to have power of at least .80 to .90. Power over .90 is not necessary for most research.
The desired level of power and what constitutes a meaningful effect size should be agreed upon prior to any study as these two pieces of information determine the sample size needed for the study. Once the study is completed, effect size and power need to be calculated to validate a priori assumptions about power and effect size. Statistical packages make such computations available with the click of a button.
Cramer’s V (for categorical data) and eta-squared (for continuous data) are among common and easy-to-interpret effect size indices. Cramer’s V and eta-squared range from 0 to 1 with larger values indicating a stronger impact of the results on business. For easier interpretation, the values could be converted to percentages by multiplying them by 100. As an illustration, consider the study on product liking discussed earlier. If eta-squared is equal to 2 percent, this would suggest that the one-point difference between the products (an average liking of 6 for one product and an average liking of 7 for another product) is not meaningful and unlikely to have business impact. Conversely, if eta-squared is found to be 30 percent, the business implication is that the one-point difference in product liking has a potential to impact the business and thus the product with a higher liking score should be selected for production.
Past research and knowledge of the research phenomena aid in determining what effect size can be expected and what impact it will have on business. As a rule of thumb, if a study investigates the relationship between attitudes and behavior, eta-squared below 20 percent is usually considered weak, while eta-squared above 50 percent represents a strong relationship.
Once the study is completed, power and effect size should be calculated and reported. They will help with interpretation of the results and aid in the design of future studies.

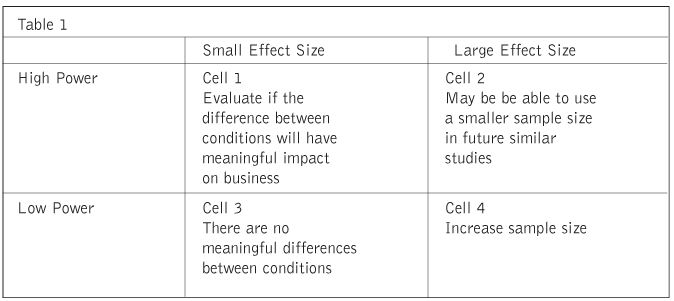
Table 1 provides suggestions based on the power and effect sizes found in a study. Cell 1 shows that if power is high but effect size is small, practical implications of the findings should be carefully considered. Cell 2 shows that if power is high and effect size is large, a smaller sample size should be considered for similar future studies. Cell 3, with small effect size and low power, demonstrates that there are no meaningful differences between conditions. Finally, Cell 4 shows that if power is low but effect size is large, there may be meaningful findings but the sample size used in the study is too small and needs to be increased before any recommendations could be provided.
Not sufficient
To conclude, information from statisical significance testing is necessary but is not sufficent. Statistical significance does not provide information about the impact of the significant result on business. This should be evaluated using an effect size index (e.g., eta-squared). Desired alpha levels, power and what constitutes a meaningful effect size should be considered prior to any study as they determine the sample size needed. Finally, power and effect size should be calculated and evaluated once the study is completed to evaluate pre-study assumptions and aid in interpretation of practical implications of the results.
References
Abelson, R. (1997). “On the Surprising Longevity of Flogged Horses: Why There is a Case For the Significance Test.” Psychological Science, vol. 8 (1), 12-15.
Cohen, J. (1992). “A Power Primer.” Journal of Psychological Bulletin, vol. 112 (1), 155-159.
Cohen, J. (1990). “Things I Have Learned (So Far).” American Psychologist, vol. 45 (12), 1304-1312.
Kirk, R. (1996). “Practical Significance: A Concept Whose Time Has Come.” Educational and Psychological Measurement, vol. 56 (5), 746-759.
Shrout, P. (1997). “Should Significance Tests Be Banned?” Psychological Science, vol. 8 (1), 1-2.