Scaling the data mountain
Editor's note: Rick Kieser is CEO of Ascribe, a Cincinnati SaaS firm. Kellan Williams is a data scientist for IBM’s Client Center for Advanced Analytics.
The mountains of data continue to grow ever higher as the world becomes more digital and connected. From sources such as social media, customer surveys, comments on the Web, etc., data is growing at a 40 percent compound annual rate, which means that the data being generated by 2020 will be more than 64 times the amount of grains of sand on all the beaches on Earth! The vast majority of what’s being generated falls under the classification of unstructured data, which requires new methods to quickly understand the meaning of what consumers or customers are talking about. (Unstructured data is information that either does not have a predefined data model or is not organized in a predefined manner. Unstructured information is typically text-heavy but may contain data such as dates, numbers and facts as well.)
Does your company have customer satisfaction or NPS surveys that ask open-ended questions, allowing the customer to reply in free-form text? Does your business have social media pages or Web forums? Nearly all companies do. After all, good businesses want to understand how customers feel about their interaction with different parts of their organizations and the information generated by these sources is invaluable in understanding the voice of the customer and tailoring the customer experience to exceed expectations.
This brings us to the problem that great companies have faced since they started trying to listen to the voice of the customer: dealing with the comments in a way that allows the business to understand what the customers are saying. Historically, most companies dealt with this by having a few employees read through the comments and try to haphazardly describe what the customer expressed in their verbatims. While being marginally effective for small amounts of comments, this method is very time-consuming, expensive and labor-intensive. While the human brain is the best tool to quickly understand what a comment is saying and to quantify the varying degrees of satisfaction, there is one flaw to using this marvelous tool: Each human processes a comment they read based on their experiences, feelings, understanding and personal context. Two people reading the same comment can have very different opinions about what it is really saying. This more random method is not very repeatable or even comparable. There are some companies that create very large codebooks and have skilled individuals reading the comments and applying this predetermined framework. These companies may also use a specific coding tool that helps in sticking to the predetermined methodology. Although time-consuming, this method can be very effective and is necessary when extreme accuracy is required.
Is there a new solution to this age-old problem? A technology called natural language processing or NLP is changing the game and enabling businesses to understand the voice of the customer like never before.
NLP is the use of algorithms that allow computers to process and understand human languages. While NLP has been around since 1950s, modern programs and products aimed at helping businesses of any size have become more readily available in the past 10 years. What are the benefits of using one of the many NLP products currently available? The algorithms they employ deliver a scientific and repeatable method of dealing with unstructured verbatims. The practical use of NLP to analyze data is also defined as text analytics.
Two of the most-used outputs of NLP/text analytics tools are concept and sentiment analysis. Concept analysis algorithms simply go through the verbatims and look for common themes or subjects being used. This can be helpful, for instance, to quickly see what are the most talked-about subjects in your most recent customer satisfaction survey or Facebook posts. Sentiment analysis takes things a step further and looks for how people are talking about the themes and concepts to assign a positive or negative score to what is being said. Many tools use a five-point scale to show the varying degree of positive or negative sentiment tied to the verbatim being analyzed.
As you can imagine, there are many tools that have very different ways of looking for and applying sentiment to verbatims. Some look at the whole verbatim or comment and give a total score. This can be effective at times but if there are several concepts or themes in one comment, looking at the comment as a whole could marginalize what the customer is actually saying. So, when looking at tools available, ensure that the NLP engine is breaking down the verbatims in a way that will enable you to extract insights from what is being said.
For example: “I love my boat but the cost of maintenance really stinks!” In this instance, there are two clearly-defined concepts or mentions you’d want to analyze and assign sentiment to. The first one – “I love my boat” – would find the word “boat” and assign the use of the word “love” to “boat,” which is classified as a positive sentiment. For the second mention – “cost of maintenance really stinks” – the algorithm would find the phrase “cost of maintenance” and assign “really stinks” to that phrase. “Really stinks” would be classified as a negative sentiment associated with “cost of maintenance.” If you looked at the sentence as a whole it would look like a neutral comment because there are both negative and positive sentiments being expressed. The more effective tools would break these mentions out to make sure the sentiment doesn’t get neutralized. To get the true meaning of the sentiment expressed you would want to see both the positive sentiment in regard to the mention of “my boat” and the negative sentiment associated with “cost of maintenance.”
Methodical approach
Of course, not all tools are created equal. In order to gain insights, consider a tool that allows intuitive and simple grouping of the key concepts to create impactful key categories that are important to your business. Use one that goes past charts and graphs to provide quantitative ways to extract insights from your data. To be sure, charts and graphs are great, but to truly gain insights from your data requires a methodical approach to under-standing the context to extract insights.
Here are key steps to getting insights out of text analytics:
- Develop a taxonomy. Set up key word groupings that are important to business strategy or core business competencies.
- Know the business and keep it simple. Don’t get too granular with the number of key groupings you are analyzing. Too much detail will make it hard to compare and gain insights from the text.
- Leverage experienced personnel. Make sure the person creating these key word groupings has a fundamental understanding of the current and future strategies and core business competencies.
- Use closed-ended variables to know the context. Attach as many useful variables to the verbatim comments as are available – for example, the day of week they interacted with your business; the product they purchased; where they live; the price they paid; the NPS score – and leverage these contextual variables to answer business questions and drive insights.
Understand context
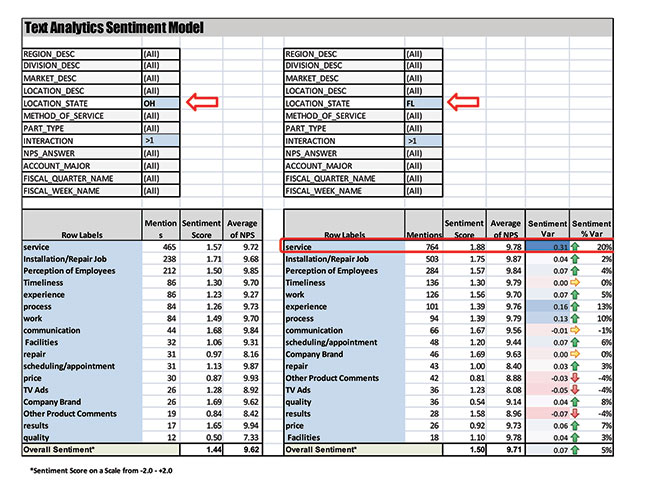
Just as with any metric, a sentiment score is not very useful unless you understand the context of why that score was given. For example, knowing that a comment has strong positive sentiment in regard to the mention of service is nice but without context it is more of a fact than it is an insight. However, if you know that the comment has strong positive sentiment on service and that the customer lives in Ohio, paid full price for the service and has used your service three times before, now you have some context!
The example depicts what we would call the base layer of being able to start getting insights from text analytics. Where you really start getting the power out of it is by next understanding how the key groupings score on sentiment or concept count in relation to the contextual variables. So, once you have the verbatims processed and grouped by key terms important to your business, use the contextual variables as filters to compare the sentiment or concepts being used by your customers. This way, you can quickly find the gaps in how certain segments or demographic groups feel about the interactions they have with your business.
Building on the previous example of the customer in Ohio, with the method we just discussed, how insightful would it be to understand that customers in Ohio who have used your service more than once score 20 percent higher on sentiment around service than customers in Florida with the same prior interaction with your business?
This step of identifying the gaps in the sentiment, or where different key groupings demonstrate an over- or under-index relative to the contextual variables, points you to where the real gold is in this treasure hunt for in-sights. After identifying the groupings that have the largest-percentage variance you now can look at the underlying comments/mentions to get the true meaning of why there is a variance and understand the real cause of the positive or negative sentiment expressed by your customers.

Returning to our scenario, after understanding that customers in Ohio have higher sentiment in regards to service, you can analyze the verbatims and find out the why. You quickly see that customers are pleased with the overall speed of service and the service mind-set of the managers they interacted with. In comparison, by looking at the same comments for Florida customers (Figure 1), you uncover that many customers are talking about the service delays they had due to long lines in several locations. You also find many customers talking about managers doing little to meet their expectations. How could this information be useful? This may inform possible areas for capital investment in new locations to meet the customer demand. It may also point to possible cross-training opportunities or best-practice sharing between the Ohio and Florida managers.

Having a repeatable methodology (Figure 2) is important if you want to compare different datasets or look at how sentiment or what customers are saying over time. Another huge benefit of modern text analytics tools is that once you create your key taxonomies, the tool will consistently group and assess sentiment the same way every time. This consistency is important, and as we discussed earlier, lack of consistency is the biggest draw-back to more manual efforts.
Hard to use
Many companies have been early adopters of text analytics, with varying results. With the new technology and tools available, why are some companies finding it hard to glean insights that improve the customer experience and lead to competitive advantages? Just as with any product, it’s only going to be as good as the individual or individuals using the tool and setting it up. Many companies are dipping their toes into the world of text analytics and handing the responsibility to interns or junior analysts with little business experience. This is a major problem! Getting actionable insights from text analytics is most successful when you enlist a data scientist who understands your business and has the abilities to creatively mine for insights.
Avoid starting out with overly complex groupings that have too many categories. Having too many key groupings will make it difficult to see the gaps in the data due to needing a decent amount of mentions in each grouping. If you spread the mentions out among too many groupings, it becomes hard to see where to dig for the true insights.
None of the work you or your team do will be valuable and used by the business unless the company culture is focused on using data to produce facts instead of relying on gut feeling. Many times the insights that come out of text analytics will uncover new ways to operate or internal changes that are needed to really listen to the voice of the customer. Unless the company is flexible and focused on implementing what the data says, the net output of the text analytics work will be seen as mere ideas instead of actionable insights.
Another very important point is that any text analytics exercise should be in service of a business question or to support key initiatives. Many times the tendency from a business stakeholder can be to say something to the effect of “Just look at the comments and see what insights you can find.” This type of request will cause frustration to both the data scientist as well as the stakeholder seeking insights. An example of a better question from a business stakeholder could be: “We’ve had a recent decline in business in the southwest region. Can you tell me if customers there have more negative sentiment in regards to our business or if they are mentioning anything that’s leading to the decline?” Direct questions lead to much more useful and relevant insights for the business. Many times the data practitioner must put the actual question being asked into more actionable terms in order to dig for insights.
A competitive advantage
With the proliferation of data – much of it unstructured – companies that get their arms around text analytics now will have a competitive advantage. To truly listen to the voice of your customer, you need to leverage the things current customers, potential clients or employees are saying about your company. To discover insights and drive change, keep building a culture within your organization of being progressive when it comes to the new data-science techniques and mining the mountains of data.