Useful data, maximized dollars
Editor’s note: Al Fitzgerald is president and founder of Answers Research, Solana Beach, Calif.
The primary goal of any researcher embarking on a study is to produce projectable conclusions while spending the least amount of money possible to complete the project. To ensure these results, wise marketers are well aware of the connection between interviewing the correct respondent and yielding accurate results, and plan study recruitment carefully.
Conceptually, one might assume that a simple random sample of a population (let’s say 18-65-year-old adults) would be the optimal approach to understand the demand for a consumer product. But this assumes that all adults have equal importance and this is not necessarily the case. For example, depending on the product, higher-income respondents may be much more likely to purchase. Therefore, researchers would be wise to oversample higher-income adults to better understand their purchasing behavior. Likewise, if we randomly sampled from a Dun & Bradstreet business list we would be equally as likely to reach small versus large firms. However, a large firm may buy 100 times as many units as a small firm - again the firms do not have equal importance in projecting demand to the market as a whole.
To give accurate weight to each type of respondent included in a study, the proper methodology is to conduct random stratified sampling. Implemented correctly, the use of this recruitment method is sure to produce useful data that maximizes interviewing dollars.
When to employ
The first factor to consider when implementing a random stratified sample is the total population to be considered in the study. This could be “U.S. businesses” or “U.S. consumers.” While the ideal recruitment approach is to conduct simple random sampling (where anyone can qualify and results appear to be most obviously projectable), within most populations are specific sub-groups that have disproportionate importance and are critical to understand.
More often than not, a product or service to be measured in a study is geared towards several specific portions of the population having varying degrees of rarity. It is then necessary to consider the sub-groups on an individual basis, and determine exactly how they vary from the characteristics of the overall population.
In a business study, a hard-to-reach sub-group could be large companies, and in a consumer study this could mean individuals in a high-income bracket. A simple random sampling approach where any U.S. business is fair game for contact would yield very few large companies, just as a consumer study where all consumers are in the contact pool would garner scant high-income survey completes. So that timing and budgets are maximized, it becomes imperative to implement a strategic random stratified sampling method.
How to employ
Once a project has been commissioned and the objectives finalized, it is critical to clearly map exactly who needs to participate in the study in order for results to be valid. Thus, well before purchasing any necessary sample, you must achieve an understanding of the discerning characteristics of each quota group to be included.
Using the random stratified sampling method, quota groups, or strata, are established to ensure that a minimum number of completed surveys are obtained for each group of interest. Simple random sampling (i.e., each individual within the sub-group sample is chosen entirely by chance) is then conducted within each of these quota groups. Finally, the data is weighted so that the proportion of each quota group in the population is also reflected in the data. The results from the study are now projectable to the overall population.
Data weighting dangers
Employing weighting, where completes are given emphasis or weight according to the size of the group within the total population, allows researchers to complete reasonably priced research. Without the ability to summarize the data that weighting provides, marketers are forced to look at very detailed sub-groups and conduct costly additional interviews - possibly missing the big picture in the process.
While weighting allows results from the sample to become projectable to the population without paying for costly interviews among rare respondents, caution should always be exercised when using the approach. Many researchers over-rely on weighting to compensate for difficult fielding. Care must be taken to not over-weight quota groups with small numbers of completes.
Case study
Suppose we are conducting a study of all businesses in the United States. Further, let’s suppose that we are going to collect n=1,000 surveys. The random sampling approach would be to obtain an unbiased sample, and then collect the surveys from this sample. Since the sample is unbiased, each member of the population has an equal chance of also being in the sample. As a result, the distribution of the sample will be the same as that of the population.
The distribution for the population of businesses in the U.S. would look like the following:
- There are many companies with one to nine employees (84 percent).
- There are relatively much fewer companies with 10 to 99 employees (14 percent).
- And there are even fewer companies with 100 or more employees (2 percent).
If the sample source is unbiased, then we would expect the 1,000 completed surveys from simple random sampling to yield 840 small companies, 140 medium companies and 20 large companies.
The results of this methodology would be completely valid and projectable to the population. However, if we were interested in looking at large companies separately, perhaps because they are more valuable than small or medium companies, we would only have 20 surveys upon which to base our conclusions. This would be insufficient. We could choose to collect more surveys until we have enough large companies, but we would need to collect a total of n=5,000 surveys in order to increase the number of large companies up to just 100. This is very inefficient from a data collection perspective. Fortunately, we can use the random stratified sampling methodology as a solution.
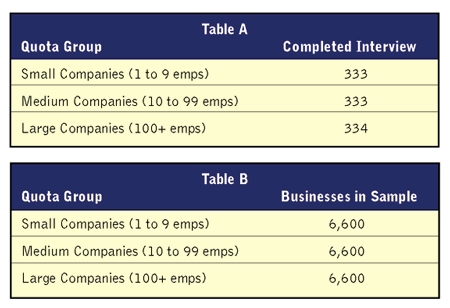
If we now apply random stratified sampling to the previous study, we would set quotas (strata) for small, medium and large companies. Since we will still collect 1,000 surveys, the quotas might be as shown in Table A.
The sample must be handled differently than with random sampling. Rather than one sample with 20,000 businesses, we need to obtain a separate sample for each quota group. Each one should be an unbiased sample for each quota group (Table B).

Simple random sampling is then conducted within each of the three quota groups. Specifically, businesses are randomly contacted within the small-company sample until the 333 small-company surveys are completed. The same is also done for medium and for large.
Now we have our 1,000 surveys, with 33.3 percent of them from small companies, 33.3 percent of them from medium companies, and 33.3 percent of them from large companies. However, the 1,000 surveys are NOT projectable to the U.S. business market. In the U.S. business market, the proportions of these company sizes are 84 percent:14 percent:2 percent, not 33.3 percent:33.3 percent:33.3 percent. The solution is that we weight the data so that the proportion of each quota group in the population is also reflected in the data.
Since small companies represent 33.3 percent of the data, but represent 84 percent of the market, we want to give them added weight in order to boost their impact from 33.3 percent up to 84 percent. Conversely, large companies represent 33.3 percent of the data, but only represent 2 percent of the market. We want to give them less weight in order to reduce their impact from 33.3 percent down to 2 percent.
With the data properly weighted, the results from the data are now projectable to the overall population. We now have the ability to analyze the data in total, as well as by company size.
It takes planning
Securing projectable results largely depends on thoroughly planning each stage of the study, including finding the correct people to interview and performing logical analysis on the collected data. No researcher wants to do fix-it work on the back end or spend their budget unnecessarily completing additional costly interviews. By implementing random stratified sampling, researchers gain just the opposite: the ability to produce projectable results, reduce the study’s fielding price tag, and include hard-to-reach respondents in their sample. And with these dividends at stake, marketers won’t mind a little extra time at the drawing board.