
SPONSORED CONTENT
Rick Kelly
Senior Vice President of Product and Research,
Fuel Cycle
 The best days of online qualitative research are yet to come. Each year, insights professionals are introduced to new research tools that enable businesses to capture organic data, organize it quickly and share insights with stakeholders. This new breed of fast-moving qualitative research tools are powered by machine learning algorithms that remove the barriers of time and cost that traditionally prevent qualitative research from being viable for nimble businesses. Yet as machine-driven online qual becomes more common, researchers (rightly) raise questions about the efficacy of this type of research over more traditional, human-centric approaches.
The best days of online qualitative research are yet to come. Each year, insights professionals are introduced to new research tools that enable businesses to capture organic data, organize it quickly and share insights with stakeholders. This new breed of fast-moving qualitative research tools are powered by machine learning algorithms that remove the barriers of time and cost that traditionally prevent qualitative research from being viable for nimble businesses. Yet as machine-driven online qual becomes more common, researchers (rightly) raise questions about the efficacy of this type of research over more traditional, human-centric approaches.
As early adopters of machine learning for the analysis of unstructured data, Fuel Cycle is often asked about our view on automated text and sentiment analysis. This article is intended to explain the approach we recommend to any new research tool (including machine learning), which can be succinctly summarized as “The tools you use should depend on the research question at hand.”
And, to further keep your attention as you read, I have included a haiku summarizing each section of the article.

Asymptotes are lines that approach a curve but never touch. In the example in figure 1, the y-axis represents certainty in research results (with the topline being perfect certainty) and the x-axis represents research costs.
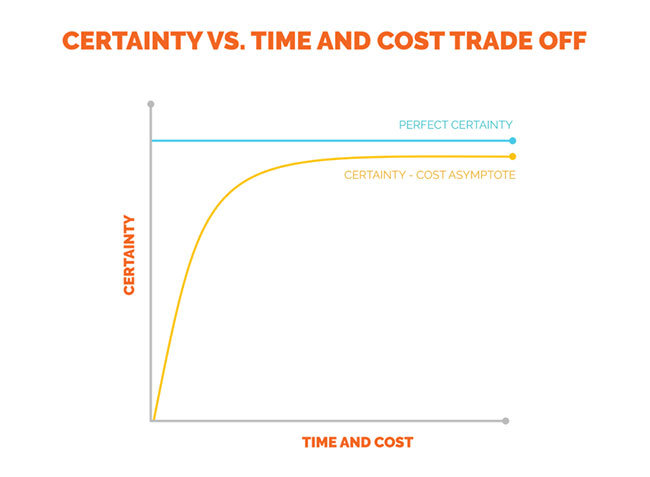
Certainty in market research is asymptotic, meaning that when we rely on a sample and human judgment, we will never approach perfect certainty no matter how much money we spend, the time we invest or Ph.D.s we hire. Even if we were to survey a population, it’s entirely possible to introduce measurement error through our research design.
One of the features of our Research Cost-Certainty Asymptote is declining marginal certainty for every increase in cost. In layman’s terms, this means that increasing certainty becomes much less cost-efficient. For instance, you increase certainty much more by increasing sample size from 500 to 1,000 than from 1,000 to 1,500. In a normally distributed sample, from n = 500 to n = 1,000, margin of error decreases from about 4.3 percent to 3.3 percent, whereas from n = 1,000 to n = 1,500, margin of error decreases from 3 percent to 2.43 percent, despite difference in both samples being an n of 500. For that reason, it rarely makes sense to increase sample sizes beyond about 1,500 people in a U.S.-based study – the gains in certainty usually aren’t worth the cost.
The result for most market researchers is there comes a point in cost that our level of certainty is “good enough” to make a decision despite not having perfect certainty in our outcome. What is “good enough” is typically determined by the research question at hand and the level of sensitivity to the outcome.
So it is with machine learning in market research, specifically when it comes to the use of text analytics, sentiment analysis and automation compared to human coding.

Fuel Cycle has been using machine learning for text analytics and sentiment analysis since late 2014. In 2018, we introduced computer vision, which uses machine learning to process images and videos uploaded to our research communities, enabling our customers to quickly analyze dozens or hundreds of images for data useful to researchers, including facial sentiment, brands, objects, landmarks and more.
Because we take a somewhat aggressive stance towards adopting new technologies, we’ve often heard some version of this statement: “Automated text analytics has a long way to go until it’s as good as manual coding.”
People tend to be surprised when they hear our response – we generally agree! As of today, there are some certainty trade-offs made when using automation for sentiment analysis compared to using human-coded responses. However, to focus on those trade-offs misses the point of using machine learning. Machine learning, when used appropriately, enables researchers to move faster and conduct research more efficiently than they’re otherwise able to.

The arguments against automated sentiment analysis and text analytics have at least some superficial parallels to the arguments made against online sampling in market research in the late 1990s and early 2000s.
Twenty years ago, many research practitioners argued that online convenience sampling from an opt-in group of respondents (market research panels) would never be as good as random digit dialing-based phone or mail surveys. There is little to no theoretical support for the concept behind online panels (convenience sampling) to make business decisions or predict election outcomes. Yet today, online sampling is used extensively to forecast election outcomes and make critical business decisions with high accuracy. This is because, in general, online convenience sampling decreased the cost of market research and allowed businesses to expand the volume of research they were conducting.
In the context of the Cost-Certainty Asymptote, online sampling decreased certainty but it also decreased cost. Researchers found a point where online sampling provided “good enough” certainty at favorable price points. Online sampling enabled researchers to conduct research with greater cost efficiency and speed than they had been able to before.

We expect researchers to increasingly adopt machine learning for unstructured data because, like online sampling, machine learning allows researchers to conduct research faster, more efficiently, with certainty that is “good enough” for many research applications.
Without reservation, Fuel Cycle believes that the research question at hand should dictate the research methodology and never the other way around. Online sampling should never replace truly random sampling for critical decisions, market sizing should never be done in a research community and automated sentiment analysis should not replace human coding for highly sensitive research. It would be a mistake to use automated analysis in an epidemiological study of rare disease patients, for instance. There are cases where increasing spending significantly to produce a slight increase in certainty makes sense.
Considering trade-offs when selecting research tools and methodologies is important. Does a 5 percent increase in certainty warrant a 200 percent increase in cost? Does a 10 percent decrease in certainty warrant an additional month of analysis?
Just because sentiment analysis isn’t a good fit for some highly sensitive studies doesn’t mean it’s not a fit for all studies. In fact, quite the opposite. We believe most commercial market research studies benefit from the use of automation because they enable researchers to conduct research faster, with greater cost efficiencies and produce certainty that is good enough for many business decisions.

www.fuelcycle.com
product@fuelcycle.com