Toward a working definition
Editor's note: C. Frederic John is principal and founder of Consilience Research & Consulting LLC, Bronxville, N.Y.
The marketing research community faces many challenges today, ranging from whether the term “research” still retains any meaning to whether the research function can be expected to survive. Generally lost in the shuffle is the declining relevance of traditional ways of classifying “research” in the broadest sense of the term, encompassing commercial activity, such as marketing and advertising research, as well as polling and public policy or social research.
Organizing research into a logical system is far more than an academic exercise, because it forces us to set the boundaries of what to include under the research rubric and what to exclude. This is particularly important as the profession has expanded dramatically in recent years, with the emergence of new types of data, methods of collecting information, forms of analysis and ways of generating insights, while the role of the professional researcher has evolved to include consulting and other activities.
Historically, research has been segmented by multiple criteria, some binary, some more complicated. A few common ways in which research has been categorized include by:
- information source – secondary vs. primary
- projectable vs. not projectable – quantitative vs. qualitative
- data collection method – in-person, phone, online, mobile, etc.
- sample frame – general public, category users, etc.
- cost structure – custom, syndicated, shared-cost (omnibus)
- general business purpose – advertising, marketing, customer satisfaction, public policy, etc.
- marketing purpose – targeting, positioning, pricing, packaging, NPD
- type of output – segmentation, new product configuration, new package design
- type of data - survey, IDIs, social media, scanning, inventory control, etc.
Any one of these ways of slicing and dicing research can be useful in a particular situation, especially when comparing alternatives. And any given project or research report could be categorized using any number of these dimensions; for example, a quantitative study among heavy brand users for targeting purposes, using three of these criteria for classifying research.
But a single typology incorporating all these (and other) ways of slicing and dicing research would have thousands of cells and little utility. I believe, however, a single classifying system is not only useful in facilitating discussions and decisions but provides real value in understanding the brave new world we are entering.
Lost their validity
Developments over the past decade have grown the field to such an extent that traditional typologies have lost much of their validity. The resulting messiness suggests that a cleaner, more relevant, “unified theory” is called for that reflects the realities of the marketplace and can retain its relevance as things continue to evolve.
These developments are driven by two forces. One reflects the rapid increase in the types and methods of collecting and analyzing data, very often lumped together as “new tools.” A second is the evolving role of the research professional from providing information (data and insights) to playing a more active role in guiding decisions. Inherent in this is the sense that the traditional neutral observer role of the researcher needs to be abandoned not only in dealing with clients but in the research process itself.
But crafting a new typology also means determining the boundaries – deciding what’s inside and what’s outside that which is to be considered. This is a sticky issue that generates considerable debate that is anything but academic. For example, it is forcing the revision of codes of conduct, affecting how research spend is calculated and changing the types of suppliers engaged by marketing departments.
Even more basically, devising a new classification system forces us to determine what aspect of the term “research” should drive the system. Is it research as a set of activities and procedures or as a set of outputs? The term is used in both ways: “We carried out an extensive research project…” “The research definitely shows that…”
Obviously, the term can be used in both ways. But it makes a huge difference in any classification attempt. Or it might demand two classification systems, one for research activities and another for research outputs. This would hardly be a simplification.
I suggest we approach the two meanings as two sides of the same coin. Research the output is the result of activities we include under the rubric of research activities. So one typology will suffice.
Why is any of this necessary or even relevant? Isn’t it just an academic exercise that will become outmoded within a few years? On the contrary, the question is particularly critical now. Professional researchers are actively seeking to establish or reestablish their identity. Their roles are evolving, the death of research loudly proclaimed by many, while visions of the “researcher of the future” proliferate.
It appears to me that delineating the research function and establishing a more rational categorization system provide real value to understanding what our role in business and society really is, not only today, but what it can be in the future. Because I also believe that there is a central core to our role that does not mutate rapidly, if at all, and will remain essential to business and society regardless of the methods used, terminology employed to describe it or way in which it is structured or financed.
So, any definition of “research” needs to meet two criteria: delineates the full range of activities that are specifically germane, if not unique, to the research function; and encompasses the full range of research output.
Set its boundaries
As with any set or cluster, it is as important to set its boundaries both in terms of the commonalities that provide its identity as well as those aspects that mark it off from others. To start, we might consider the following question: What functions does the professional researcher carry out that would generally be considered a research activity? These would certainly include the following:
- assessing the objectives of an inquiry
- designing the inquiry, including selecting the appropriate data-collection method
- sampling
- writing the questionnaire, guide, etc.
- interviewing, moderating, leading discussions, etc.
- collecting or generating data or information from other types of sources
- processing and/or evaluating data/information collected or generated
- producing insights, conclusions and implications based on data or information collected
- writing reports
- presenting findings, conclusions, recommendations
What emerges from this exercise is that the role of the research professional involves either an intellectual component, the application of specific skills or, in many cases, both. But in order to be considered “research,” many of these activities need to be part of a larger process that ultimately produces a piece of “research.” For example, collecting data that are never analyzed should not be considered research. This is particularly important when considering the passive capture of information. A supermarket scanner that collects data that are never processed or interpreted can hardly be considered a research activity.
How about the consulting role provided by many researchers? In and of itself, this is certainly not unique to the researcher but is arguably an essential component of being a professional researcher. For that, one needs to look at context. Consulting/advice based on information/learning generated by another research activity (such as a survey) remains within the core of our profession. Advice based purely on experience, knowledge of a category or derived from anecdotal or the cursory gathering of opinion is not.
There are obviously fine lines and grey areas that might only be determined on a case-by-case basis. But in general, the creation and analysis of information by rigorous means must be part and parcel of the equation.
In terms of what to include as research output, I think we need to include any forms of data that are produced and treated in some way. This would cover data that have been aggregated or organized, analyzed or subjected to more vigorous analyses, as well as the display of these activities, whether on a screen or in cross-tabs, tables and charts, etc., or in written descriptions. It would also include written (or spoken) descriptions of insights and conclusions derived from the data, as well as implications and recommendations specific to the client.
Based on all of this, I propose two somewhat extended definitions of the type of research we are discussing:
1. “Any activity directly involved in the careful, systematic study and investigation of a subject undertaken to discover or establish facts or general principles.”
2. “Any results of such activity, including data that have been analyzed, organized or interpreted and written assessments of the learning that emerges from the new data or information that has been collected or generated.”
Having decided upon what to include under the research rubric, we can finally return to the question of how this universe can best be sliced and diced.
Setting priorities
The key to establishing a new, rational, and useful research typology is essentially one of setting priorities. What criteria are really important in dividing up the field – both as activity and output – and what are secondary or even irrelevant? Here is my proposed solution.
The first basic dimension needs to reflect the accuracy of the output. Historically, we have looked at the projectability of the information to a defined universe as a measure of accuracy and quantitative methods as the means of achieving this. Many now argue that 1) projectable results are very difficult to produce and may be less meaningful than previously thought and 2) relevant learning can emerge from purely qualitative or subjective methods.
Taking the second point first, we need to consider the nature of different types of output – the what, the why and the what if.
In absolute terms, it makes a difference whether descriptions of reality (the what) produced by research are reflections of a larger marketplace reality or only reflect the perceptions/experiences of a subset that can’t be projected onto the market as a whole. But there may be cases where clients may settle for an “indication” that is an imperfect measure of reality.
This perceived lack of relevance of representative sampling takes on even greater importance when the focus shifts from data to explanations of motivation (the whys), which are also often derived from qualitative means. Such an insight that arises out of a more rigorous exercise should probably be given more weight than one based on a pair of focus groups that may best be treated as hypotheses.
Future projections – particularly the likely response to a new offering – are by nature hypothetical and surrounded by caveats. But the degree to which these predictions are accurate, either within the market as a whole or among a specific group, is critical to their value to clients.
Finally, implications/recommendations/consulting are essentially freed from projectability, since they are not data but assessments of what course a company should pursue, based on multiple factors beyond data or information, including experience, understanding of the dynamics of the category, strengths of the brand and/or corporate reputation, etc.
So where does this lead us? I propose that one fundamental dimension of the new typology should reflect the probable accuracy of the output within a defined universe. This would fall on a continuum from highly probable to not at all probable.
For statistical data, this essentially coincides with projectability. But for information that arises from other types of means, such as the learning that emerges from focus groups, online communities or from other small or unrepresentative samples, or insights that emerge in the course of a project, projectability cannot be measured but only expressed in subjective terms. There may be good reason to believe a certain revelation is truly universal even if this cannot (yet) be proved. Simply assigning such a finding a low projectability score may not be doing it justice. But we can assess its probable accuracy.
This approach also mitigates the first barrier cited above – the practical problem of producing predictive sampling/producing projectable results.
The second dimension should reflect the basic nature of information capture or generation. Rather than enumerate a raft of methods, I propose this be boiled down to a single aspect – whether the capture/generation is active vs. passive. Traditional research behavior, built on the scientific method and willing participation of the respondent, assumed an active data capture. The emergence of other forms of information streams, such as social media, scanning data and other forms of big data, and tapping into these as sources of information and insights, has radically changed the landscape.
This is not to judge that active is superior to passive but that radically different approaches are employed between the two and quite distinct ways of evaluating the data and treating the results are required.
The third dimension should reflect basic purpose. Again, this should not be a laundry list of marketing or other goals but reflect the nature of the output itself. I propose a continuum that runs from assessment of factual information to the creation of something new.
At one end of the spectrum, you would have essentially the what data or information, regardless of source. It could be purchase data based on scanning, attitudinal information based on a questionnaire or focus group discussion, hotel satisfaction data based on a totally unrepresentative sample of visitors or self-reported product usage data, etc.
Further down the continuum you would get into the explanatory “why” information, which could be derived from multivariate analyses, IDIs or group sessions, exit polls, brain scans or other sources. Much of this would be devoted to motivation. But it would also include circumstantial information such as distribution or availability that play a large role in determining brands purchased. It would also include “insights” relating to deeper understanding of the underlying structure of a market.
Still further along on the continuum, you come to what-if or prediction aspects, such as tests of new concepts or products, followed by the creation of wholly new configurations through optimization techniques. Finally, you come to fully creative exercises, in which participants develop their own visions for products.
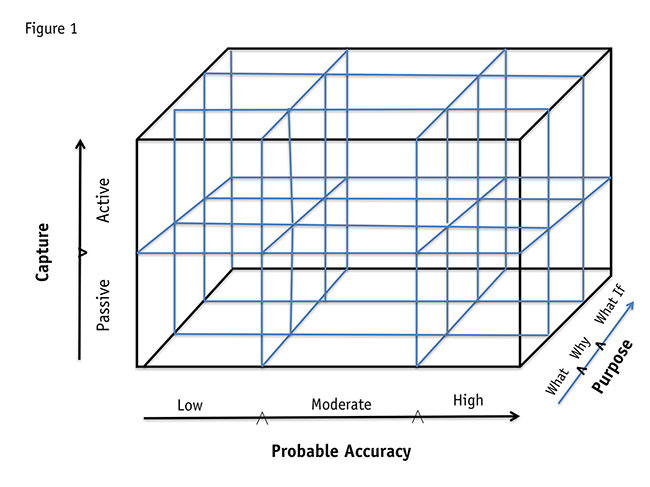
Where do we end up? With a three-dimensional cube, with each axis representing one of the three dimensions described above and broken into two or more parts. For the sake of discussion, imagine a cube with 18 cells, as follows:
Dimension 1: probable accuracy
Three pieces: high, moderate, low
Dimension 2: nature of capture
Two pieces: active, passive
Dimension 3: ultimate purpose
Three pieces: what, why, what if
Accordingly, any research initiative or output can be assigned to (at least) one of these cells.

Simplifies our thinking
Just how useful is such a typology? I would suggest it greatly simplifies our thinking and speaking about myriad types of research activity and output. Such a framework helps structure conversations with clients, who often have preconceived ideas of what they want done or get lost in discussions of multiple methodological approaches. In such discussions, and in our designing of projects, we can systematically run through the three dimensions and relatively quickly isolate the type of approach needed and then develop a plan to meet those criteria.
So the conversation might touch on these aspects:
- Just how accurate do the results have to be to meet your objectives?
- Can the information required to answer the objectives be best met from an active, primary research approach or can the answers be gleaned from existing information or other data streams?
- And just what type of information are we seeking along the continuum from “what” to “what if”?
Once determined, and agreed to, the design can be fleshed out, costed and approved.
Here are three hypothetical situations demonstrating how the typology could be successfully deployed.
CPG rebranding
A mouthwash manufacturer feels its brand is a me-too brand in a ho-hum category. It wants to conduct research that will help it find ways to bring excitement to the brand. In discussions with the research team, it is agreed that: best outcomes are creative ideas that will stimulate buzz; the project requires original research; and they should rely on “brand champions.”
The researcher places the need within the typology as follows:
- Probable accuracy: low. Focus on totally unrepresentative sample.
- Nature of capture: active.
- Ultimate purpose: what-if/creating something new.
Once the cell is established, the researcher recommends establishing an online community of brand champions as the creative engine, with ongoing input and interaction with the client team.
B2B targeting
A U.K. provider of liability insurance to larger enterprises wants to expand into the small-business sector, focusing its efforts on the most rewarding segment. While information exists about the number and type of small businesses, no data are available about the use of, spending on or interest in purchasing liability insurance.
In discussions with the research team, it is agreed that: output must identify specific segment(s) of the market that are best targets; the results must be highly accurate; and only original research can provide the missing information, to be combined with census data.
The researcher places the need within the typology as follows:
- Probable accuracy: high. Large sample weighted to reflect census data.
- Nature of capture: active.
- Ultimate purpose: what.
The researcher recommends a large-scale market segmentation study based on a stratified random sample of a wide cross-section of small enterprises.
Hotel usage study
A global hotel chain with an active loyalty program wants to measure what factors drive overall usage (nights stayed and total spend) among its members. In discussions with the research team, it is agreed that: output will identify demographic, corpographic (for business travelers) and other variables that predict degree of usage; and the universe will be limited to current loyalty program members.
The researcher places the need within the typology as follows:
- Probable accuracy: fairly high, reflecting membership base.
- Nature of capture: passive. Existing data sources sufficient.
- Ultimate purpose: why.
The researcher proposes an intense analysis of multiple data sources, including hotel usage and spend, information provided on the original loyalty membership application and information that can be purchased regarding individual members. The ultimate purpose would be to identify predictors of heavy hotel usage
Stimulates further discussion
I am confident many will take issue with various aspects of what I am proposing – with the criteria for determining what is and is not research, with the three dimensions of the typology and the ways in which they can be divided. That is fine. My purpose has been to demonstrate the value of and need for such a system, not to offer the one-and-only solution. If this piece stimulates further discussion and alternative definitions and typologies, I will feel I have accomplished what I set out to do.