
Can I trust you?
Editor's note: Lisa Horwich is the founder and managing partner of Pallas Research Associates.
With all the hype around using AI for research, wise researchers may want to step back and ask: Can I trust this vendor’s application? We, as research professionals, are not necessarily equipped with the knowledge to effectively evaluate these systems. We don’t spend our days worrying about governance and compliance, data privacy or cybersecurity. This article outlines steps you can take to help you measure an AI application’s trustworthiness to confidently assess the latest AI research tech.
The National Institute of Standards and Technology (NIST) has put together a framework that can help researchers evaluate the trustworthiness of an AI system.1 By utilizing a framework, we can help minimize the risk and negative consequences that could arise from an application that doesn’t adhere to cybersecurity or data privacy standards and best practices.
As shown in Figure 1, NIST’s characteristics of trustworthy AI include the following parts: safe; secure and resilient; accountable and transparent; explainable and interpretable; privacy-enhanced; fair – with harmful bias managed. In addition, as the basis for the other trustworthy characteristics, any AI system must be valid and reliable. We will cover each of these in detail.
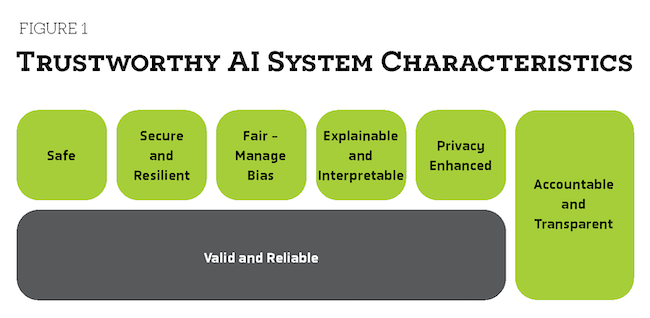
According to NIST, “Addressing AI trustworthiness characteristics individually will not ensure AI system trustworthiness; trade-offs are usually involved, rarely do all characteristics apply in every setting and some will be more or less important in any given situation. Ultimately, trustworthiness is a social concept that ranges across a spectrum and is only as strong as its weakest characteristics.”2
Organizations must decide on the trade-offs that matter most to them, balancing company goals with company values. Under certain conditions, achieving privacy might be more important than overcoming bias, while other times, especially with sparse data sets, data privacy is sacrificed for validity and accuracy. These are decisions that each organization must make, using human judgment.
Let’s explore each characteristic.
Valid and reliable
As the basis for the other characteristics of trustworthiness, an AI system’s validity and reliability are paramount to minimizing failures that could cause potential harm. These failures can be “hallucinations,” where the AI makes up answers; it could be overgeneralizations or data leaks where confidential information makes it outside of the application.
We want to look for systems that are accurate – meaning their results can be applicable beyond the training data and can minimize false positives/negatives. They are also reliable, which allows them to work under any conditions, even those that are unexpected.
Safe
The concept of safety is less of a consideration for researchers but comes into context when thinking about autonomous systems like self-driving cars. In those situations, the AI system should have risk-management approaches like rigorous simulation, real-time monitoring and the ability for human intervention in systems that deviate from intended functionality.
Researchers should look for systems that are designed responsibly with distinctly outlined instructions on correct use as well as having all risks clearly documented.
Secure and resilient
Cybersecurity risks and threats fall under an umbrella concept of “vulnerability management” – this is what keeps most IT leaders up at night. Many of these risks are ones that can affect any organization, not just ones that develop AI applications. These include external attacks like hacking, ransomware, distributed denial of service or phishing.
We want to ensure that any vendor who has access to our data is taking precautions to protect it – by encrypting the data both in transit (uploading/downloading across the internet) and at rest (where it’s stored). We also want their websites to withstand external attacks with firewalls that are periodically tested proactively with penetration (“pen”) testing. Finally, we want to know they are controlling access to the data with techniques such as multifactor authentication – like those codes your bank sends to your phone.
If an AI system can withstand these types of risks and maintain its functionality, it is said to be resilient. The system can carry out its mission even if an unknown or uncorrected security vulnerability enables an attacker to compromise the system or an external environmental condition (like the loss of electrical supply or excessive temperature) disrupts the service.
Fair
A system that is fair is free from bias. Biases can be systemic, computational and statistical or human-cognitive. Systemic bias can be present within any portion of the AI life cycle, from the datasets used to train the foundation models all the way to the broader population that uses AI for analysis and decision-making. Computational and statistical bias tends to be present when non-representational sample is used. Finally, human-cognitive bias occurs when individuals or groups use an AI system to make a decision or fill in missing information.
Fairness tends to be less of an issue with market research because, while we as researchers want to have a representational data set, we often are not using AI to make decisions that directly affect outcomes, like applying for a job or trying to obtain a loan. Nonetheless, researchers should be cognizant of the inherent biases we might encounter with AI systems’ design, implementation and operation. We must manage this bias and account for it when using AI for analysis.
Accountable and transparent
For an AI system to be accountable, it needs to be transparent. This can be a significant issue with the foundation models from OpenAI and Anthropic that form the basis of many of the applications we use today (like ChatGPT or Claude). These organizations closely guard their IP by purposely obscuring the data and the compute layers that make up the model.
Meaningful transparency would provide us important information at each stage of the AI life cycle. We would then understand design decisions and the underlying training data as well as the structure of the model, how it’s trained, its intended use cases plus how and when deployment, post-deployment or end-user decisions were made and by whom.
But putting this into practice is very difficult, as discussed in a recent Wall Street Journal article:
“A lot of the mystery is that we just don’t know what’s in our pretraining data,” says Sarah Hooker, director of Cohere for AI. “That lack of knowledge comes from two factors. First, many AI companies are no longer revealing what’s in their pretraining data. Also, these pretraining data sets are so big (think: all the text available on the open web) that when we ask the AIs trained on them any given question, it’s difficult to know if the answer just happens to be in that ocean of data already.”3
We must demand accountability from our application vendors who, in turn, can put pressure on the foundation model companies to be more transparent. This will allow us to have a better understanding of “what happened” in the system when analyzing output – especially when it might not make sense to us.
Explainable and interpretable
Being able to explain and interpret AI output helps us understand the purposes and potential impact of an AI system. Right now, for systems that are obscure (remember many AI foundation models are proprietary to preserve their IP) data goes into a “black box” and a result comes out, often without any rationalization.
AI systems that are explainable can answer the question of “how” a decision was made within the system. They can rationalize the output by giving us the steps it took to reach the answer. My favorite example is an AI system which has an input of a bug and says it’s an insect without any explanation vs. one that shows the bug and explains that it has six legs, therefore it is an insect – not an arachnid (Figure 2).
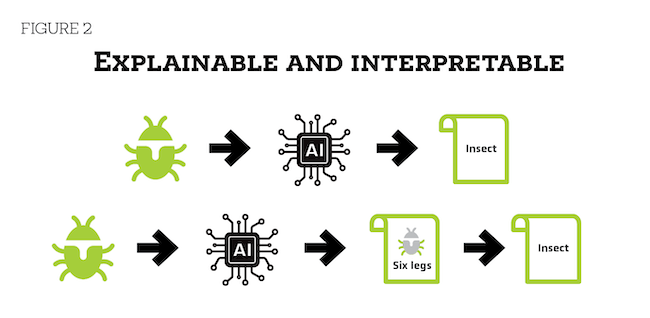
The advantage of explainable systems is they can be debugged and monitored more easily; they tend to have more thorough documentation, auditing and governance. This is especially important for highly regulated industries like health care and finance.
One thing to keep in mind is that systems don’t necessarily have to be explainable during processing – we can interpret them after the fact. Ask yourself, does the analysis or output make sense? In the case of qualitative research, is the output consistent with what you heard in your interviews or focus groups. For quantitative research, does the analysis match the data collected?
Privacy-enhanced
The final characteristic of a trustworthy AI system is privacy. Data privacy is paramount in our work as researchers. We have to follow privacy rules and regulations that span multiple geographies (think GDPR, CCPA and others) or face huge fines for non-compliance.
AI systems now have the ability, through linking seemingly disparate data sets, to potentially infer an individual identity or information that was previously private. We should look for AI systems that are designed, developed and deployed using privacy values such as anonymity, confidentiality and control. In addition, these systems should implement privacy enhancing technologies like minimizing methods such as de-identification and aggregation for certain model outputs.
What we really want is something called privacy by design. These are systems with privacy considered before development starts versus a system where privacy is added after the fact. In the case of AI being added to an application, was privacy already part of the application before AI or is privacy now a concern to be solved?
And, of course, follow the stringent privacy laws such as GDPR and CCPA.
Data compliance standards
While not part of the NIST trustworthy AI system framework, knowing the different types of data compliance standards can help us assess whether an AI foundation model or application can be trusted.
The main compliance criteria we should be looking for are:
- ISO 27001: This standard from the International Organization for Standardization governs information assets and ensures that adequate information security managements systems are in place to safeguard data.
- SOC2/SOC3: These two System and Organizational Controls rules outline the policies and procedures organizations must follow to protect customer data. These controls are audited by the American Institute of Certified Public Accountants (AICPA) to guarantee they meet the AICPA trust services criteria.
- HIPAA privacy rules: For anyone conducting research in the health care arena, following the Health Insurance Portability and Accountability Act regulations is paramount to working with patient data. The creation of this national standard was designed to protect sensitive patient health information from being disclosed without the patient’s consent or knowledge.
Ask these questions
With this framework and overview of terms, you can develop a checklist for accessing both new tools and your current vendors. Before trusting your confidential and private data to an AI application, you should ask the vendor these questions and they should be able to answer within the standards this article outlined:
- What are you doing with my data?
- How are you adhering to data privacy laws?
- How are you protecting my data? Specifically, what cybersecurity measures are you taking to protect my data?
Any vendor should have this information readily available on their website – it’s usually under terms of service and/or privacy (often in teeny tiny type at the bottom). Seek out specifics – claims of a walled garden aren’t enough; ask how the data is protected inside that garden and how the data is coming into the garden. Read through the legalese to ensure they have implemented policies and procedures to safeguard your data. Also, make sure they are SOC2/SOC3-compliant and are following ISO 27001. And read the audit reports to ensure nothing egregious has been flagged. They should be published on the vendor’s website. If not, ask for them.
Have your vendor explain how their application addresses each of NIST’s characteristics of trustworthy AI and make sure their reasoning fits within your organization’s goals and values. If you are vendor, please make this information readily available.
References
1 NIST (2023) “Trustworthy and Responsible AI: Overview” https://www.nist.gov/trustworthy-and-responsible-ai
2 NIST Speech (2023) “Launch of the NIST AI Risk Management Framework” January 26. Available at: https://www.nist.gov/speech-testimony/launch-nist-ai-risk-management-framework
3 Christopher Mims (2023) “How does AI ‘think’? We are only just beginning to understand that.” The Wall Street Journal, October 22. Available at: https://www.wsj.com/tech/ai/how-does-ai-think-95f6381b