Editor’s note: Scott MacLean is director of data science at Nulink Analytics, Melbourne, Australia.
A lot of good things come from New Zealand: Bungee jumping; EasiYo make-your-own yogurt; the All Blacks; Begaand Mainland cheese; good sauvignon blanc wines; Crowded House; and Russell Crowe (well, maybe not the last one).
New Zealand also produces creative and competitive ideas pursued by skilled and knowledgeable market researchers.
The latest I have come across is a rather cool online tool developed by Irene Rix and her business partner Josh Bondy, at their aptly named CodeKiwi business, albeit based in Melbourne (I have no formal or financial connection with this company).
Some of you will know that I can go on a bit about the quality of data files that I am given to analyze. Indeed, some of the leading interviewing packages still don’t seem to have understood the idea that their great online interview scripting capability can still result in data files that are painful to analyze.
In most cases, asking your data provider to give you output in SPSS .sav format will minimize my pain (and that of any analyst) but not always. In any case, a lot of times I still receive data files in .csv or .xlsx format, and that can raise a whole lot of issues that normally just don’t occur with SPSS data:
- no labeling information for code frames or questions;
- answers to multi-response questions recorded in just one field, with responses separated by commas;
- pick any responses recorded as one, two, three, etc. instead of 0/1.
I could go on.
In most cases, I therefore prefer to refer people to the excellent guide to SPSS data file preparation, available on the Survey Analysis Web site.
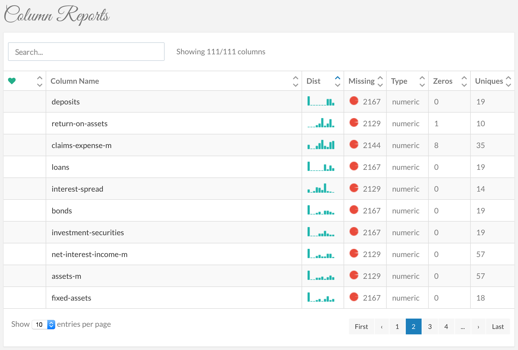
The CodeKiwi team’s approach, in contrast, stems from their recognition that in the wider data and analytics field, the .csv (and .txt) data file format, is pretty much pervasive. Their online tool allows anyone (not just market researchers and analysts) to upload these types of data files, have comprehensive and automatic checks and reports run on the data structure; format; missing value patterns; distributional forms and characteristics; values requiring re-coding; string lengths; and a host of other information.

In addition, a unique data health index is provided. This index is based on the pattern of missing values, mix of variable types and their skew, variance and concentration of values.
In their own words:
“Knowing your data before you get started can save hours of pain. Learn what’s lurking in that shiny new data file, and save your time for the clever stuff …”
The Know thy data initiative is a first-rate effort to come to grips with a key issue that is faced by all data analysts, whether in market research or in other fields of data endeavor.
Why not have a look for yourself? https://knowthydata.io/