
Like humans, only smarter
Editor's note: Jerry Thomas is president and chief executive of Arlington, Texas-based research firm Decision Analyst Inc.
 The business news outlets are cluttered with stories about artificial intelligence (AI) and machine learning (ML) startups. Major corporations are rushing to set up internal teams and divisions to exploit AI and machine learning. Graduate schools are turning out data scientists and business analysts with training in the two areas.
The business news outlets are cluttered with stories about artificial intelligence (AI) and machine learning (ML) startups. Major corporations are rushing to set up internal teams and divisions to exploit AI and machine learning. Graduate schools are turning out data scientists and business analysts with training in the two areas.
The big technology companies are creating AI software and systems. Marketing executives are anxious to apply AI and ML to optimize marketing and advertising processes and programs. It’s as though the gods have descended from the heavens to share ultimate truth with we humans.
But what is artificial intelligence and how does it relate to machine learning? What do these terms mean?
Intelligence, whatever it is, is presumed to reside inside of biological creatures (cells, bacteria, plants, animals, insects, humans). We don’t think of intelligence as something possessed by a rock or a mineral or other non-living substances. All biological creatures can make decisions or choices that increase their chances of survival. Let’s define intelligence, then, as an ability to make a decision, to choose among alternative paths or possibilities in order to achieve some objective.
Artificial, in this context, means non-living or non-biological. So AI is an ability of some non-biological entity (machine, computer, software, system, algorithm) to make choices or trigger actions that help solve a problem or achieve an objective. We’ll come to “machine learning” later.
The beginning of modern artificial intelligence, as it is now commonly thought of, traces its origins to the development of computers during and following World War II and the possibilities spawned by those machines. The arrival of these powerful machines gave rise to much thinking about what intelligence is and whether machines might be able to “think like humans think.”
Virtually all computer languages and programs, with their ability to compare variables and values and change the flow of logic to achieve some objective or trigger certain outputs meet the above definition of AI. These programs are non-biological and make “decisions” to achieve objectives.
The definition of AI, however, continues to evolve and expand. The current definition and understanding tends to mean machines (broadly defined) that simulate or mirror human thinking. The simulation of human thinking is a much higher standard for what AI is or could be. The recognition and translation of human speech into text is a good example of AI-derived models that closely simulate a human’s mental capability. Image and pattern recognition are, likewise, human feats that AI can increasingly derive models to mimic. Voice-to-text translation and image recognition, however, are only the tips of the iceberg.
AI is, or will be, applied to developing and improving models to perform medical diagnoses, conduct legal research, do data mining and predictive analytics, analyze business processes, detect fraud, predict market trends, forecast sales and so on. The possibilities are endless.
Great promise and hope
Machine learning is closely related to AI and the two terms are often used as synonyms. With machine learning, computers can “teach themselves” how to simulate processes and decisions. It is the arrival and development of machine learning that offers such great promise and hope. If computers can program themselves or create solutions themselves, then AI can be applied to an array of problems and processes very economically and very quickly. Machine learning is the linchpin technology that could open up many new applications and allow AI to spread rapidly. So what is machine learning and how does it work?
Machine learning requires some goal or objective; that is, a dependent variable (or multiple dependent variables). The more narrow and specific the dependent variable(s), the greater the chance(s) that machine learning can derive a formula, equation or mathematical algorithm that helps optimize (or maximize) the dependent variable(s).
The dependent variable could be something as simple as the response rate to a direct mail promotional offer. Or, the dependent variable could be classifying photos into two groups: those containing an image of a chair and those without an image of a chair. Regardless of the type of dependent variable(s), we must have some way to determine if the dependent-variable prediction is better (or correct) during each iteration of the model derived by machine learning.
Machine learning also requires a substantial and relevant database of independent variables that might predict or explain the dependent variable(s). The better the independent database in terms of completeness, relevance and accuracy, the greater the chances that machine learning will be able to build a good mathematical model.
In the response-rate prediction example, the independent variables could include things like household demographics, weather data, mail-delivery days and times, economic data, marketing research data and historical details about the various mail pieces (claims, type of graphics, colors, length of copy, type font, etc.) used in the past and the resulting response rates.
The bulk of the work and most of the costs related to machine learning revolve around creating a high-quality database of independent variables with data for each variable over a substantial number of cases or over a substantial period of time. In some instances this is weeks or months but in other cases years or decades. Once this database is assembled and cleaned, we have a dependent variable (response rate), an objective (maximize response rate) and a database of potential explanatory (independent) variables with extensive and clean historical data for each variable including past results. But, we are not yet ready to push the “go” button on the computer.
Machine learning also requires a computational strategy. Computers are dumb and thoughtless. Without a strategy, computers could easily grind away on a dataset for thousands of years without achieving anything. There are many possible models that might be employed as the machine-learning algorithm, including: regression analyses; decision trees; support vector networks; ensemble models; gradient boosting methods; neural networks; Bayesian networks and deep learning.
The computational algorithm could be one of these statistical techniques or it could be combinations of these techniques (i.e., hybrid models) or it could be completely different techniques but the human mind has to give the machine-learning system some type of strategy. There are easily more than 100 existing statistical routines or techniques that might form this computational strategy – and thousands more to be created in the future, no doubt.
Now it’s time to put the machine learning to work. The computer begins to run calculations following the assigned strategy or strategies. In each iteration the model estimates the response rate (or other outcomes), compares the predicted outcomes to actual outcomes and tweaks the model to improve its predictive accuracy. This iterative process of model improvement is continuous so that the predictive model becomes better and better over time. Figure 1 shows a simplified diagram of a machine-learning system.
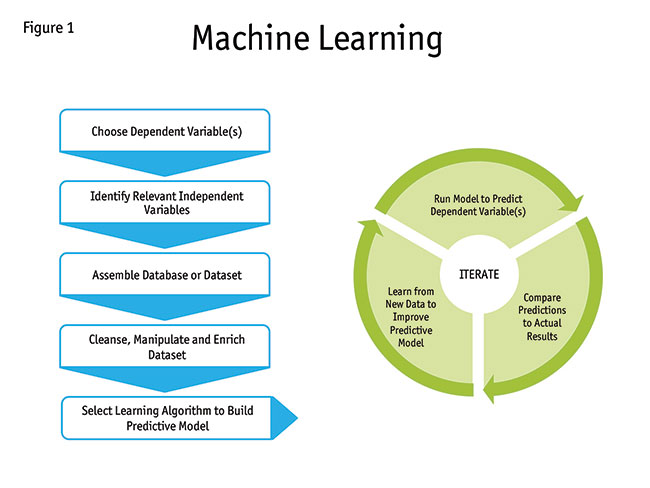
One other point: During the early stages of model development, how can the accuracy of the new machine learning model be tested? Back when the original database of dependent variable(s) and independent variables was created, you were very clever and randomly chose a holdout dataset (also called a validation dataset), a random subset of the original database. The holdout dataset allows you to test your new machine-learning model to see how well it works.
The actual response rate for this holdout data set is known, so you have a benchmark, a measuring stick, to determine how good your new machine-learning model is at predicting the actual response rate. In the other example – classifying photos into those with a picture and those without – the same process would be followed. The original set of photos would be divided into a training data set and a holdout or validation data set and a huge database of possible predictive or explanatory variables would be created.
Human judgment would determine which photos contained chairs in the training data set and human judgment would determine which photos in the validation data set pictured chairs. The machine-learning model(s) would be judged, ultimately, by how well each model identified photos with images of chairs.
Not magical solutions
There you have it. Now you can pretend to be an expert on AI and machine learning. As is evident, artificial intelligence and machine learning offer promise for the future but they are not magical solutions to all the world’s questions and problems. We must wait a while longer for the gods to reveal the ultimate truth to those of us in the long-suffering human race.