Finding the strength in numbers
Editor’s note: Steven Gittelman is president, and Elaine Trimarchi is executive vice president, of Mktg, Inc., an East Islip, N.Y., research firm.
The very nature of survey research requires that online sample sources have robust quality standards. It is impossible to interpret market research results with confidence without a thorough understanding of the sample sources from which respondents are drawn. This is particularly important in the case of both tracking studies and multinational studies, where both validity and consistency are critical.
Since late 2007, our firm has been compiling and analyzing data for just such an assessment. The Grand Mean Project is an extensive study of global online panels. For the study, at least 400 respondents are collected from each participating panel. A standard online questionnaire, translated into local languages, is utilized, including a focus on buying behavior and a broad spectrum of other subjects. This program has collected data on more than 150 panels across 35 countries. In eight countries, at least five companies have participated, allowing the creation of a grand mean. In 17 countries, multiple panel data has been collected and in 10 countries one panel has participated. To our knowledge, it is the largest and most comprehensive online sample assessment to date.
Metrics must be reliable
Not all measures and references meet the requirements for auditing metrics. Being interesting and meaningful is only part of the equation. Metrics also must be reliable across multiple executions, panel types and countries.
Our objective is to measure differences in the panels, not necessarily differences in respondent opinions. Opinions may vary for any number of reasons. We need to measure variation due to the sample itself; variation due to drift - changes in the underlying sample over time - must be minimized. To minimize drift, we moved away from single-variable measures and are combining questions to create a more stable and robust metric.
Metrics must be global in that they cross international borders. For the purposes of market research we believe that the focus should be on buyer behavior and sociographic variables. Measurements should not require complete recalibration for each subsequent test. The measures should stand on their own and not require redefinition.
Increasing level of bias
A recent disruptive concept in survey research is the absence of a true probability sampling frame. While this is particularly the case in online research, even traditional telephone survey sampling contains an increasing level of bias.
That said, samples are typically quota-controlled for census-based demographics. But the underlying source of respondents is not drawn from a census. This is true to a varying extent for all types of data sources.
In the online sample context, the goal is to find a reference standard that can be used in lieu of the outdated telephone “gold standard.” The grand mean is the average value of all available panel data for a country or region. The overall average is the mean of available panels from a single source. This metric is the reference for consistency testing.
Three basic issues
There are three basic issues that must be addressed regarding panel stability, performance and quality: the effectiveness of quota controls in matching targeted demographics; the frequency of troublesome respondent characteristics; and examining the differences in the buyer behaviors and sociographic attitudes to understand the means by which the sample sources differ and how they might change over time.
For quality audit purposes, single-variable metrics tend to be unstable and may be less “reliable” than using combinations of variables for quality audits. There is stability in diversity; combinations of variables are less susceptible to outside influences. For example, the willingness to purchase a single commodity may vary due to local economic conditions, or, more importantly, changes in the marketplace over time.
This problem is most associated with attitudes and behavior, while fact-based information, such as demographics, is less susceptible. We are particularly interested in the stability of behavioral distributions; particularly purchase behavior, the key variable most market research is designed to measure.
We have used a form of structural and market segmentation to provide stable metrics for attitude and behavior issues. The structural segments are based on 30 or more variables covering a specific area of potential interest. Three segments we have used in this research are: buyer behavior, sociographic factors and media use.
Capture the variability
For the purposes of this article we will be referring to the data source as “Test Panel.” This panel comes from a major supplier of online respondents for commercial surveys.
The objective of this program was to capture the variability over time in the use of a single source of online respondents. Test Panel provided samples on three occasions (December 2007, May 2008 and May 2009). On each date Test Panel supplied sample for the completion of 400 interviews.
The testing procedures were based on the execution of a standard questionnaire. Questions were selected to allow a consistent standard and independent assessment of the panel or data source. In this and all other cases, samples were provided by the source supplier using deliberate instructions to use their standard methods of respondent management and incentive delivery.
The internal reference for analysis is based on a moving average of the data series1. Note that this is a bootstrapping process, where the internal reference is recomputed for each consistency report. As more data in the series is available, the average reference values are expected to become increasingly stable. A one-year moving average is used.
Measures of structural characteristics of the panels and data sources are best reflected by the distribution of attributes rather than single-point values. These include the demographic and segmentation characteristics. However, due to the multiple values of these distributions, the collective measures of comparisons are necessary in order to highlight differences and to establish consistency measures.
• Variation and error. Stacked bar charts are used to show the time-series results of the sample set along with the appropriate references.
• Distance measure of variation. The root-mean-square distance2 measure is used to indicate detail in the differences between distributions. A measure of the expected error3 is also given. This is useful to distinguish between statistically significant differences and those that are important in terms of consistency. Note that due to the use of two standard errors, this is a strong test for inconsistency4.
Within the error bounds
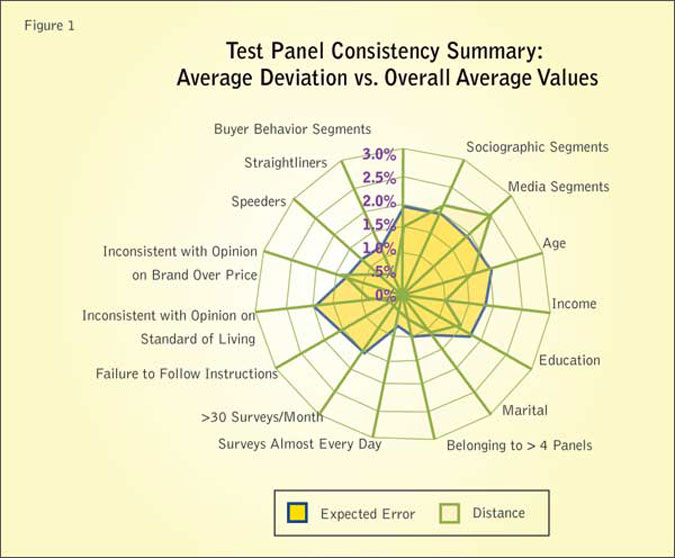
The results of the average consistency of the sample sets compared to the overall error bound for the various metrics are shown in Figure 1. In terms of overall consistency, 87 percent of the metrics (13 out 15) for the average deviation across Test Panel sample sets were within the error bounds5. When considering only larger inconsistencies (greater than a 25 percent discrepancy over one standard error) this becomes 93 percent, with only one metric significantly outside the error bounds. The largest percent contributor to the overall average inconsistency across sample sets is media segments, with a 25 percent difference from the expected error.
One would expect the demographics of a sample to reflect the population. For these sample sets, quotas were requested based on census data. Unless there was some error in the process, the resulting demographic distributions of these quota-controlled variables should be in line with those of the population. Age and household income were controlled by quota in this study. However, there were several other demographic characteristics measured that should be aligned with the reference though they were not controlled by quota including: education and marital status.
We use the distribution of education to illustrate demographic consistency analysis. Note that educational attainment levels were not quota-controlled. As such, they are likely to vary between the source data and grand mean.
Figure 2 compares the education achievement distribution for Test Panel to the overall average and the grand mean. The error ranges are indicated by the vertical black lines at the end of the groups. There does appear to be difference between the May 2009 sample set and the overall average values6.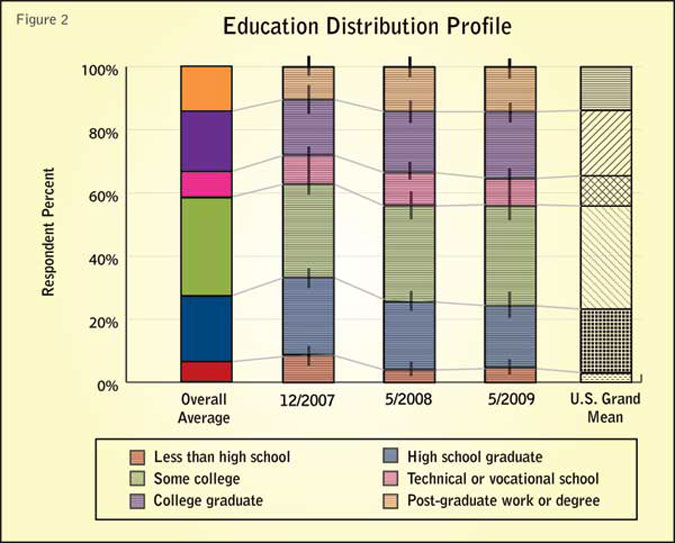
More details on the deviation can be seen on the distance measures shown in Figure 3. The distances between all sets and the grand mean are below the expected error.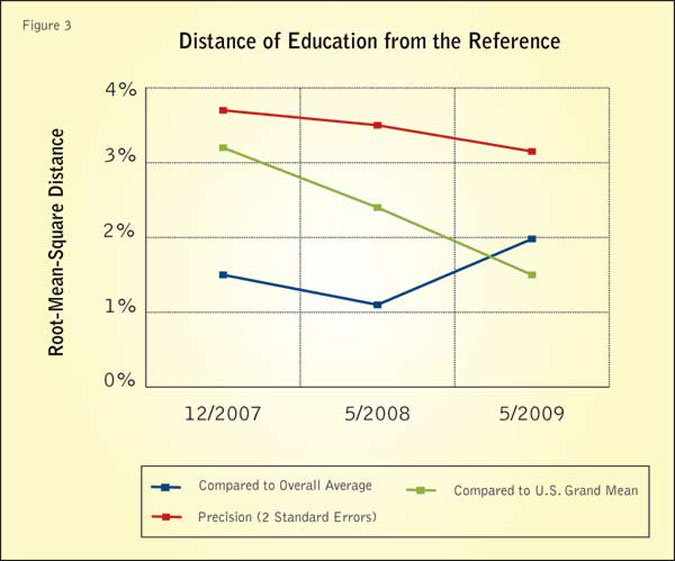
Filtered to balance
In the previous section, we examined demographic measures to assess consistency of sources over time. These reflect the operations of the sample source but not the consistency of the respondents. Typically, online sample sources are filtered to balance demographics against some external standard such as the known general population. However, this does not ensure that the source maintains the targeted group of respondents.
Structural segmentation is designed to capture the distribution of groups, or segments, of respondents which, if different, are expected to impact the studies executed using these sample sources.
As mentioned, we used three segmentation schemes in this evaluation, 1) buyer behavior, 2) sociographic factors, and 3) media use factors.
We use the analysis of the buyer behavior segments to illustrate consistency auditing. The buyer behavior segments are intended to capture the variability in the attitudes and actions regarding the purchase of a broad range of products.
The standardized profiles for the selected U.S. sources are shown in Figure 4 and reflect the response to 37 input variables.
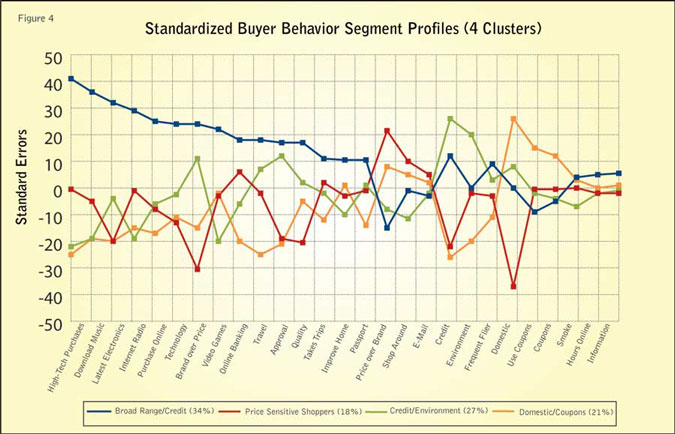
The titles of the segments are drawn from the variables of greatest impact for the segment. The purpose of this scheme is to reflect differences between sources of data and the general grand mean representing that region.
It is important to note that the distribution of these segments is expected to and indeed does vary widely between different countries and global regions. However, we expect the distribution of these segments among sources within regions to be less variable. Furthermore, we expect the distribution of segments to be consistent over time within a panel or source.
Figure 5 compares the buyer segment distributions for Test Panel and the overall average and the grand mean. As with the other variables, the error ranges are indicated by the vertical black lines at the end of the groups. There does not appear to be a major difference7 between the May 2009 sample set and the overall average value in the buyer behavior segment distribution.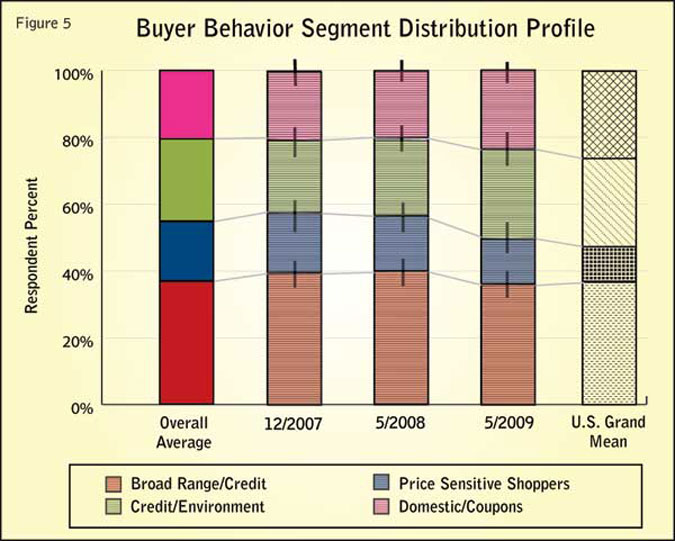
More details on the deviation can be seen on the distance measures shown in Figure 6. The distances between all sets and the overall average are below the expected error.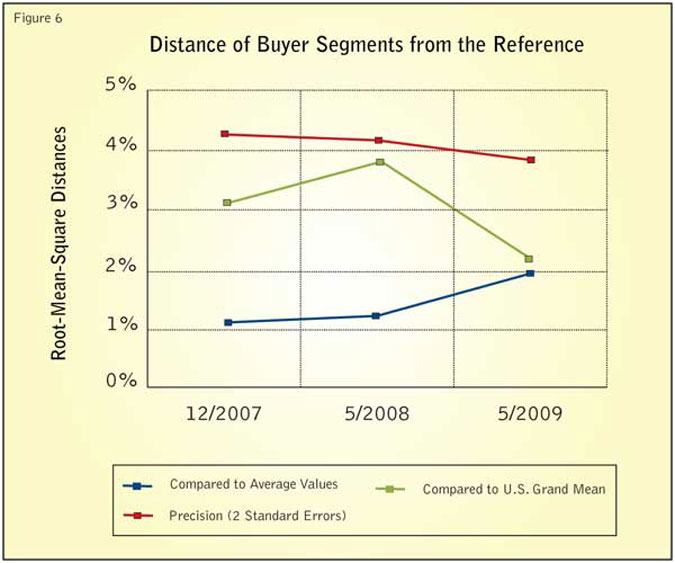
Fundamental issues
There are several types of metrics that provide measures of effective panel and respondent behavior. As mentioned, these are often fundamental issues reflecting the mechanism of generating and encouraging participants. While each of these measures reflects the propensity of respondents to generate erroneous responses, each one in isolation may only be a random error. However, we would expect the appearance of these effects to be consistent.
There are three basic sets of respondent behavior: performance, characteristics and satisficing. The incidence of errors in the execution of questionnaires reflects the quality of the panel and is referred to as performance. These are quality checks designed into the test instrument. They include but are not limited to: 1) inconsistency in responding to multiple questions and 2) failure to follow instructions.
The characteristics or structure reflect the nature of the participants in the panels. In general, these focus on issues and concerns with the long-term maintenance and in particularly the tendency to contain professional survey-takers. These metrics may include participants who belong to multiple panels, have been on panels for an extended period of time or who take multiple surveys frequently.
Respondents occasionally show extraordinary characteristics. These are not errors, just extreme behavior, which warns of the possibility that questions are being skimmed with little thought behind the answers. These are referred to as satisficing behaviors and include: speeders, who finish their questionnaire in extraordinarily short time, and straightliners, who tend to give the same answer to a large number of questions.
The quality of results for Test Panel compared to the references is measured by the frequency of improper responses. The quality of survey results is often difficult to measure. In this testing procedure, specific trap questions were used that allow for a measure of improper action. The test instrument has two types of items: 1) questions with designated answers that require specific action; the failure to do so is viewed as a violation, and 2) inconsistencies, where two balanced but opposite questions are asked; answering both strongly positive or both strongly negative is another type of violation. Figure 7 shows the results for the Test Panel sample sets and the references.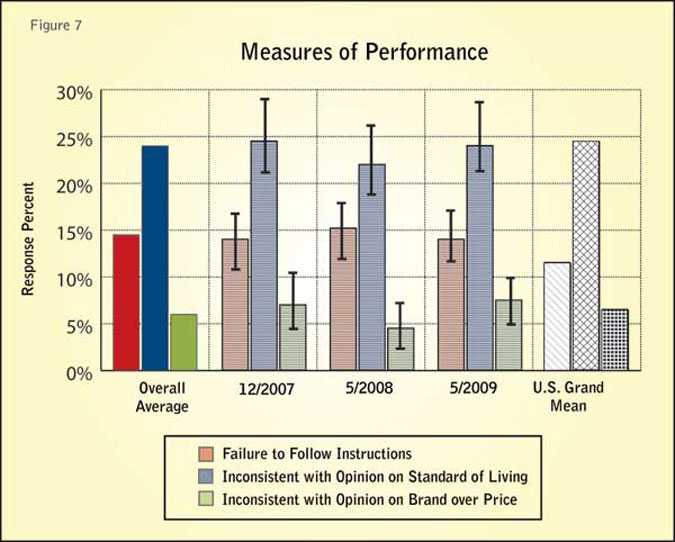
The questionnaire had one instructional or trap question where the respondent was specifically required to enter a specific set of values. If an improper response was given, the incident is considered a “failure to follow instructions.” The other two measures capture inconsistent responses: happy/unhappy with standard of living and brand over price/price over brand. As noted above, these measures are based on having given either strong positive or strong negative values in both directions.
The control chart in Figure 8 indicates the occurrence of respondents failing to follow instructions for the Test Panel sample sets, and it illustrates the consistency testing of the performance factor. The black line represents the occurrence rates. The bars are the error range (95 percent confidence level). The red line indicates the overall average, and the green line is the grand mean reference.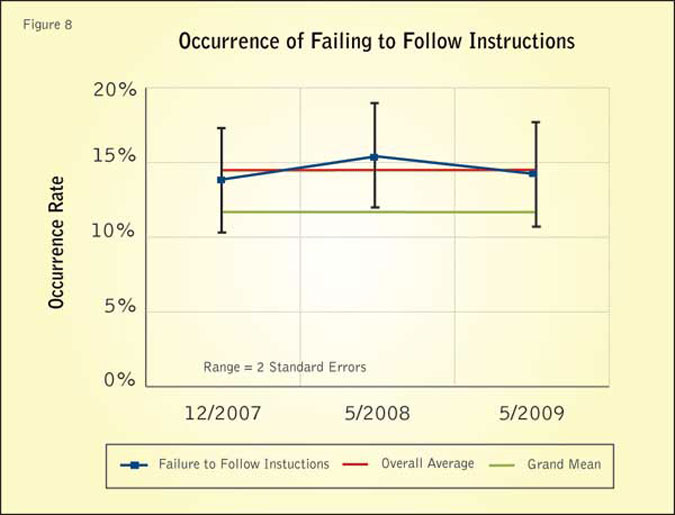
The deviation of all respondents failing to follow instructions for Test Panel sample sets compared to the overall average was within the expected error. The largest deviation from the grand mean for failing to follow instructions beyond the error bound is 0.2 percent for the May 2008 sample set.
Hyperactive survey respondents are members of panel or other online data sources who take surveys too frequently. Hyperactive respondents are measured here in four ways: 1) belonging to five or more panels; 2) taking surveys almost every day; 3) having taken at least 30 surveys in the past month; and 4) relatively long panel tenure. As self-assessments, these measures could be in error, but they do represent consistent metrics.
Figure 9 shows the results for the Test Panel sample sets and the references for the occurrence of frequent survey takers. Notice that the grand mean values are much higher than this data source. This indicates that the members of this source are less susceptible to frequent survey-taking, and they belong to fewer panels than the general online community represented by the grand mean.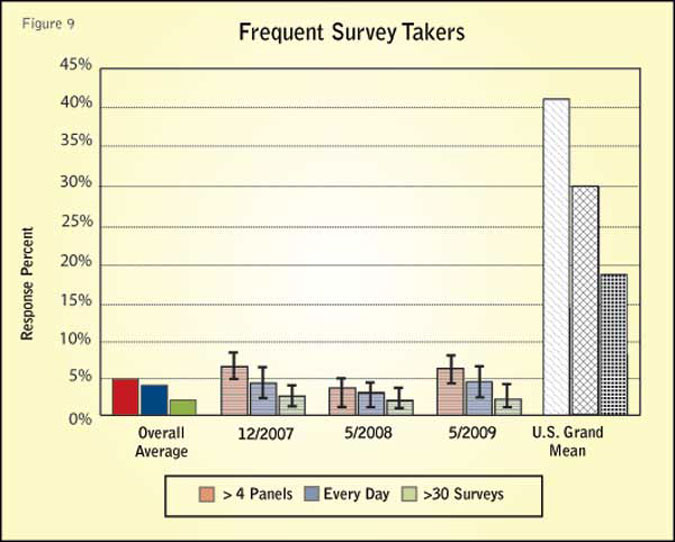
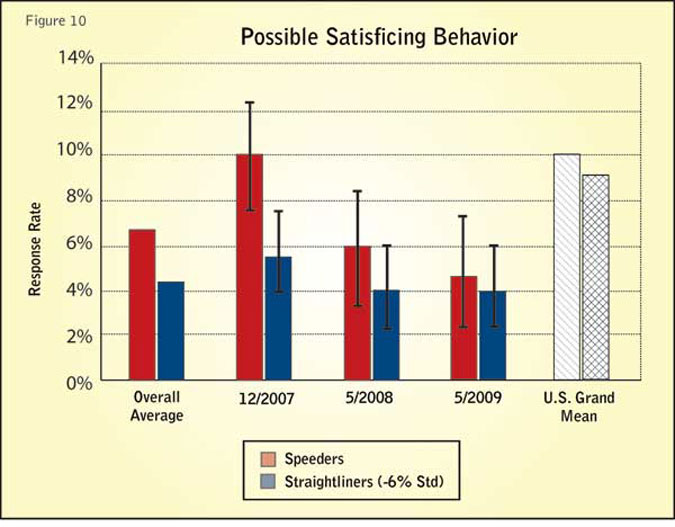
So far our analysis of performance characteristics has focused on errors made by respondents in their participation in surveys and panels. There is a third category of activities that is thought to likely affect the quality of results. These are participants who either speed through the survey (speeders) or those who give similar or identical values to blocks of questions in the surveys (straightliners). These respondents can be viewed as potential satisficers. However, once again, there is no direct evidence that such behavior results in poor-quality survey results.
Figure 10 shows the overall results for the Test Panel sample sets and the references for the occurrence of satisficing behavior. Consistency testing is shown on the following control charts, indicating the performance of each sample set with the same corresponding error bound as used here, along with indications for the overall average and the grand mean references.
The control chart in Figure 11 indicates the occurrence of respondents being speeders for the Test Panel sample sets, and illustrates this kind of analysis. The largest deviation from the overall average for being speeders beyond the error bound is 1 percent for the December 2007 sample set. The deviation of all respondents being speeders for Test Panel sample sets compared to the grand mean was within the expected error.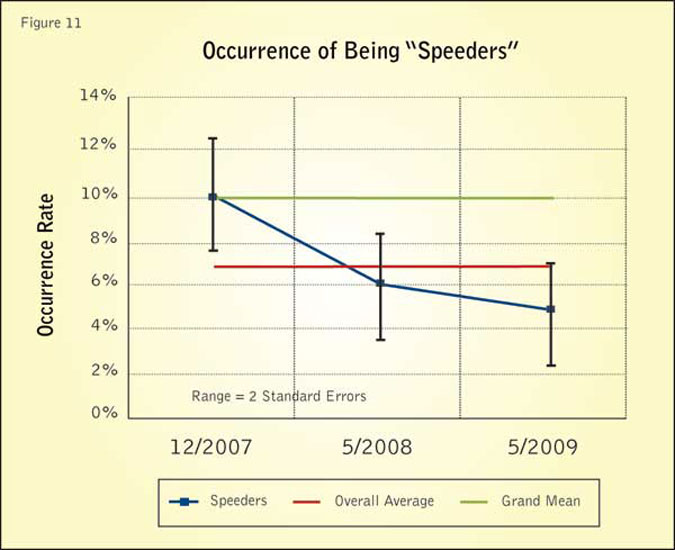
A new era
Online market research has moved into a new era, from a probabilistic framework to “working without a net.” The explosion of online research is not the root cause of the erosion of our probabilistic framework; its origins go far deeper. Random-digit-dialed samples once provided this industry with the ability to relate back to a sampling frame rooted in the census. If we made enough callbacks, converted refusals and adhered to strict calling patterns it was possible to approach a random selection of households that seemingly gave us a reasonable facsimile of a probabilistic world. Alas, phone research would have run into trouble as technology confounded its very way of being. It was nice while it lasted but mobile phones have proliferated to a degree that pure telephone sampling just cannot carry the day: there are too many non-landline-using respondents.
Online research has been troubled from its advent. Our fondest wishes cannot grant it a true probabilistic frame: the offline population is different from those online. Early on we turned to phone-online comparisons to provide credibility to our new format. One has to wonder if our efforts were not misguided in the first place. As the telephone standard drifted from gold to brass we were seeking a safety net in the wrong place. Telephone built itself on the back of earlier methodologies and by now would have suffered its own sordid demise. To compare online to telephone is misleading. The question arises: Is there a true probabilistic sampling frame remaining in market research?
In the absence of a probabilistic net to anchor samples, they can drift without our knowing. It is appropriate for the industry to run parallel studies on panel sources to measure consistency through time. We propose that the grand mean allows us to compare the results from consistency measures, grounding them in a dual metric. Shifts that may be measured can be used to clarify changes that might appear in normal tracking work.
In an ideal world, all panels would regularly test for consistency. Their combined consistency data could be compiled to generate a grand mean within a market as a new reference to anchor panels and tracking studies alike. The composite data would provide rich insights into shifting in the sample universe and inconsistencies within individual panels. If needed, source-blending using optimization modeling could serve to correct drift. Consistent bias (the mere use of the word “bias” brings a shudder) could be monitored against the metric. The opportunity exists to anchor our research, bringing light to a situation that currently lacks transparency.
References
1 This is not typical for most quality-control situations, where the reference is usually set at some requirement or specification, and is therefore automatically fixed. In this case, the historical average was used and therefore, varies between consistency reports.
2 The root-mean-square distance is defined as the square root of the average of square of the differences between the distributions elements.
3 These are taken as the square root of the average of the squared errors (note that these are taken as two standard errors).
4 The chi-square test indicates the likelihood that two distributions of values are the same. It is a collective test of consistency based on variation. This is usually also given as a comparison between the various datasets and the references. However, it tends to emphasize specific differences. While the chi-square measures are useful to provide a broad view of the fit between distributions, it does not yield details of the fit. It does show the degree of fit.
5 Deviations: Distributed parameters are based on the root-mean-squared value of the deviations. Single-valued variables are taken as the simple difference between the value and the reference. Error range: The error range for the distributed parameters were taken as the root-mean-squared values of the standard errors.
6 Based on the c2 statistics, which measure the significance of the difference between distributions, the largest deviation was a 37 percent agreement for the May 2009 sample set and the overall average distribution. The largest deviation was a 0 percent agreement for the December 2007 sample set and the grand mean distribution.
7 However, the significance, if any, needs to be explored based on the c2 test below. Based on the c2 statistics the largest deviation was a 65 percent agreement for the 5/2009 sample set compared to the overall average distribution for the buyer behavior segments. The largest deviation was a 5 percent agreement for the 5/2008 sample set compared to the grand mean distribution.