
AI and market research
Author: Orkan Dolay, Director Business Integration and Development, Bilendi and respondi
![]() In 2019, I began an article for a German research magazine by stating:
In 2019, I began an article for a German research magazine by stating:
“The term ‘artificial intelligence’ leads some people to expect a great deal. The word ‘intelligence’ suggests that the intelligence of humans is to be artificially recreated. That machines will take over the activities of humans and will perform these activities better and more reliably. But that is not yet the case. In the short- and medium-term, artificial intelligence will not primarily take over the intelligent tasks from market researchers, but rather the simple, non-intelligent tasks.”
Then, along came large language models (LLMs) …
The AI landscape in 2023
Now, in 2023, we stand at an exciting juncture in AI development. Prior to the advent of LLMs like ChatGPT, even advanced AI solutions like IBM Watson and Google BERT were essentially performing linear extrapolations, relying on probabilistic models. These AI systems required extensive training, particularly for tasks such as categorizing verbatims (coding) and sentiment analysis. Achieving satisfactory accuracy for market research involved training these systems topic by topic and context by context. For instance, "olive oil" in the context of food differs significantly from its application in skin care products.
Take Google BERT, for instance. Our colleagues trained BERT using three years of web browsing data (URLs collected from our panelists while they were using the internet) and let him learn autonomously. Then they asked a question … "Cristiano Ronaldo?"
BERT knew that Cristiano Ronaldo was a footballer, No. 7, and played for Manchester United, etc. Clever. However, BERT then assumed the reverse was also true. That football + Manchester United + 7 also equaled “Cristiano Ronaldo.” It returned articles for us that had nothing to do with Cristiano Ronaldo, but with the incumbent No. 7 of Manchester United. Not so clever after all.
Our AI accuracy test
In recent years, we have been utilizing the Google API for sentiment analysis, which is an integral component of the Google NLP suite and is seamlessly integrated into our in-house online qualitative software, Bilendi Discuss.
Simultaneously, we embarked on the training of our proprietary model named BARI, built upon the foundation of Google BERT. Our subsequent actions encompassed conducting a series of tests. In our projects, participants were frequently requested to rate a product or service on a 10-point scale and subsequently provide an explanation or justification for the assigned rating. This process generated a substantial volume of data, which proved immensely potent for evaluating the precision of sentiment analysis. The strength of this data lay in its ability to facilitate an accurate assessment, as each verbatim corresponded to a specific rating.
Subsequently, we employed a standard categorization prevalent in sentiment analysis: very negative, somewhat negative, neutral, somewhat positive and very positive. We considered these categories to align with the 10-point scale, as illustrated below.
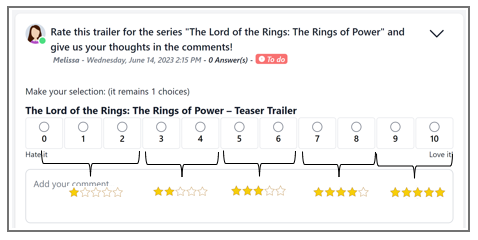
We tested a data set of 167k pairs of comments and ratings derived from various large-scale qualitative studies.
To simplify matters for the sentiment analysis models, we focused solely on the two top and bottom ratings. The “negative” 1- or 2-star categories were grouped together, as well as the “positive” 4- or 5-star categories. This alignment corresponds to the standard threefold classification of sentiments: positive, neutral and negative.
In essence, the aim of the test was to determine how accurately the AI would guess the rating based on the verbatim we provided.
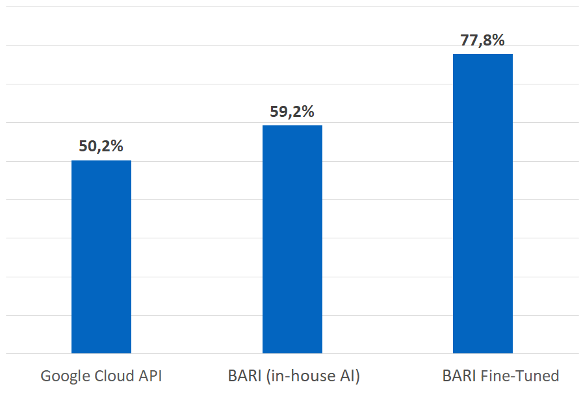
As you can see, on this specific task our in-house models – in particular the fine-tuned model – outperformed the Google Cloud API in terms of accuracy.
Now the game is changing. But how will it change?
The main difference is that LLMs are generalist and generative. Generalist means that they do not need to be trained with a huge amount of data. We can use their existing knowledge immediately. Even if we wish to adjust the models for a specific task, this is feasible with some few-shots-learning. When we provide them with some examples, they understand the logic of what’s expected and deliver acceptable results. Generative means that they generate “new” content. Before they simply classified what was there already.
Two kinds of LLMs and their potential benefits for market research
1. Text-to-image generation (Midjourney, DALL-E, etc.).
Those tools turn ideas into pictures. Thanks to the way they are built, they are especially good at illustrating stereotypes, style imitation and finding creative ways to mix universes and references. Arguably, it is this third point that makes them really “creative.”
Here’s a non-market research example to get a sense of their potential.

Image source: Falcon, Midjourney Showcase, “A bedroom melting into the ocean”
Midjourney produced an image based on the prompt, “A bedroom melting into the ocean.” As we can see, the machine was smart enough to identify the curtains as the best transition point between furniture and water.
In market research, we mostly need pictures for illustration purposes, e.g., as part of market segmentation, when it comes to helping clients perceive the personas that emerge. When segments are described in abstract terms (sociodemographic, attitude, etc.), it is sometimes difficult for clients to grasp the gist of the segment. But as they say, “a picture is worth a thousand words,” and one may use text-to-image generation tools to turn a cluster description into a flesh-and-bones persona. This is a good use case because personas typically are based on a mix of stereotypes, something text-to-image generators deal with well.
The image below was generated for a French Bilendi project to illustrate a segment of the so-called "empêchés" (people with a burden). People in this segment could benefit from home services (cleaning, etc.) but do not have the energy and abilities to organize them. They’re so overwhelmed that they don’t have the time and energy to organize some support, like childcare. The image says it all in one fell swoop: gender, age and attitude.

2. Text-to-text generation (ChatGPT, Bard, etc.).
What we speak most about in the industry is using ChatGPT or Google Bard as a kind of junior researcher or personal research assistant. Basically, those models are good at "following on." Given some input, they have been extensively trained at following that input. In its early stages qualitative research typically takes that form:
1) We are given some materials (typically, verbatims).
2) We are given some research goals.
3) We need to address those goals on the basis of the materials.
However, a current limitation of ChatGPT and similar models is that they have limited self-organizational properties. To perform well, they need step-by-step guidance to accomplish complex tasks.
We found it useful to break down a researcher's task into elementary steps that ChatGPT can follow in order to provide "not just a summary" but an insightful analysis of a discussion topic.
We asked ChatGPT to analyze verbatims by providing:
- A general summary.
- A categorization of answers into type.
- Quotes illustrating each of the types.
- Explanations of the attitudes that could explain those illustrative quotes.
A real-world example of using ChatGPT to analyze qual research
As part of a study on 'constrained' consumption, we asked 250 participants whether they are changing their habits out of concern for the environment. Here is what our ChatGPT turned qual tool provided:
a. Summary.
“Participants in the online qualitative research have given mixed responses to whether ecological issues have changed the way they do their shopping. Some have made significant changes in their shopping habits, such as buying eco-friendly and recyclable products, reducing meat consumption, buying locally produced items, avoiding plastic and palm oil, and boycotting animal testing. Others have made minimal or no changes, citing cost, availability, and convenience as factors. The rest have made slight changes, such as avoiding excessive packaging, using reusable bags and checking for recyclable packaging.”
b. Answer types.
1. No Change
2 Minimal Change
3. Significant Change
4. Mixed Responses
c. Quotes.
Here the AI provided a description for the second category, minimal change:
“Participants who made slight changes in their shopping habits cited avoiding excessive packaging, using reusable bags, and checking for recyclable packaging as factors.”
As well as identifying some verbatims to illustrate the group:
“I reuse bags.”
“I guess I might choose different items if I think the packaging is greener and the cost is the same.”
“I buy fruits that are not packaged.”
d. An explanation.
“The participants who made slight changes in their shopping habits, such as avoiding excessive packaging and using reusable bags, have a moderate level of concern for the environment. They are aware of the issues but not necessarily motivated enough to make drastic changes. They may also face barriers such as lack of information or options.”
We can see that given the right instruction; generative AI can be leveraged at key steps in qual research. However, we are still far from general AI (AI that would be all-purpose smart the way humans are), so it's essential to know to use those models, building on their strengths and circumventing their limitations.
Let’s get back to our AI accuracy test.
As shown above, first we only looked at things people say to justify their rating and asked the AI to guess whether the rating was good or not based on the commentary.
We wanted to see what would happen if we extended this to verbatims that were not rating comments. Like spontaneous evaluation or more objective thoughts about any given topic.
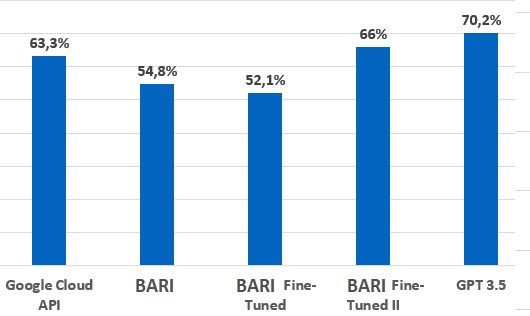
In this test, our in-house fine-tuned model didn’t perform as well, because it's only been trained on the basis of rating comments. Interestingly it performed less well than the original BARI. A typical case of so-called “overfitting.” Here the Google Cloud API performed much better. Consequently, we made a second fine-tuned version of our model where we adjusted the training. This improved things a lot and we're back to being better than Google … but not as good as GPT 3.5.
Then we made things a bit more difficult for the AI. In neutral verbatims, there are, in fact, two kinds of verbatims. The neutral because of mixed feelings. And the neutral because the verbatim is simply an objective statement. They are not the same thing. So, we created a third fine-tuned model and tested the ability of different AIs to distinguish explicitly between the two, to be able to tell the market researcher which verbatims express an evaluation and which are really descriptive.
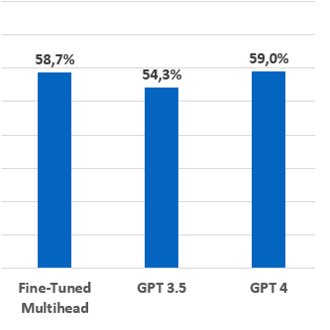
Our third fine-tuned model outperformed GPT 3.5 … but not GPT 4. A lot is said about GPT 4 not being an improved version of GPT 3.5. In fact, on this specific task, it is.
The (current) limitations of LLMs
To make it work you need to break the tasks down to several smaller subtasks. The art of prompting lies therein. AI is not at the point where it is actually intelligent. It can’t do a full research report and it isn’t even close to it. But it can extract the essential or similar traits from available data. It is getting better and better at it. 
Yann Lecun, chief AI scientist at META, says, “Nobody will use ChatGPT in five years” and that “ChatGPT is not that innovative!” Big talk, but certainty we will see new solutions from tech giants and significant updates from established models that push the boundaries on a regular basis.
Risks in the use of AI
A lot of articles already deal with privacy and ethical issues. I won’t pick through this again. But besides these ethical questions, one risk for market research (and other industries) is the “alienation effect” – placing our jobs into the hands of machines. If these machines do tasks traditionally given to researchers at the start of their careers, (reading through the materials, structuring and organizing them, summarizing, etc.), how will the next generation of senior human researchers learn?
Another risk is what one can call over trust. Or the Tesla effect. It’s part of natural human thinking that if something works well most of the time, it will never completely fail. But even if there’s only a risk of 1 out of 1,000, the damage might be huge. AI “hallucinations” are a well-known phenomenon and pose a significant risk to the integrity of research and the reputation of researchers.
Recognizing true intelligence
The Cambridge Dictionary defines intelligence as “the ability to learn, understand and make judgments or have opinions that are based on reason.” The essential part of this definition is, for me, to make "judgements” and to act accordingly, to derive purposeful action from it. This requires "real" intelligence for the foreseeable future. An intelligent activity for which humans will have more time and better foundations, thanks to automation and AIs that will take over the intellectually less demanding, time-consuming and redundant tasks of structuring and summarizing data and information.