Editor’s note: Jeroen Hardon is research director and Kees van der Wagt is senior research director at SKIM, Rotterdam, Netherlands.
In conjoint analysis we can use different models to predict choice. The one most often used is a random utility model (RUM), in which consumers select the product that offers them the best combination of product characteristics. But RUM has some shortcomings. This article explores the integration of RUM with another model, random regret modelling (RRM), to create a more robust and accurate model. RRM assumes that, rather than going for the optimal product, consumers aim to minimize the potential regret of missing out on certain product characteristics.
Both approaches have their pros and cons and both are more or less suitable in different market situations. In an effort to improve the predictive validity of conjoint results, SKIM researchers compared and combined RUM and RRM by means of two case studies and posed the question: Would the hybrid solution lead to more realistic results?
Introduction to RUM
RUM is widely used to estimate the preferences (i.e., utilities) of different product characteristics, also referred to as product attributes such as price, brand, size, etc. It is based on the principle that a consumer chooses one product that has the best combination of attributes (i.e., the maximum value of utilities) and is dependent on which attributes matter most to him or her.
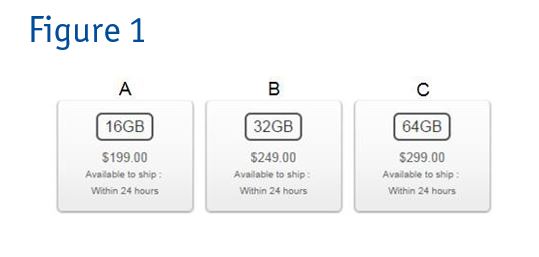
Let’s assume we are in the market to buy an iPod. There are three products: A, B and C. (Figure 1).

The total utility value for Product A is the sum of how much someone values the 16GB storage space and the price of $199, and so on for Products B and C. The product with the highest utility gets chosen.
This model works well but it has its limitations. For one, it assumes that choices are based solely on optimizing the combination of characteristics of the product they select, independent of alternative products that are available in the market. It does not take the context of the chosen product into account.
Introduction to RRM
Using RRM is one way to minimize the limitations of RUM. RRM is based on the assumption that instead of choosing the option with the best combination of product characteristics, consumers make choices in order to avoid the potential regret of missing out on something. The RRM model assumes that as soon as people make trade-offs, they run the risk of regret. Usually there is at least one non-chosen alternative that outperforms a chosen product on one or more characteristics (e.g., it is cheaper, prettier or performs better).
Again, let’s use the iPod example. Product B has 16GB more storage compared to Product A and Product B has 32GB less storage space compared to Product C. In RRM, Product B has a 0 + 32 = 32 regret on GB. Product C has no regret at all on data storage. Increasing Product C to 128GB storage would do nothing for its regret but it would affect the regret of the other alternatives because it increases the amount of storage that one misses out on when selecting Product A or B.
RRM tends to be more suitable in categories where the purchaser is more likely to explain their choice or when other people are involved. However, RRM also has its clear drawbacks. For one, it may be less suitable when an opt-out alternative (“none of these”) is used. Since the opt-out is not described by different levels, one cannot calculate the regret. Only ordinal attributes can be coded as regret. For example, how would one code the regret of unlimited amount of minutes vs. 250 minutes in a telecom study? In practice, this means that RRM is not applicable for many product categories and characteristics.
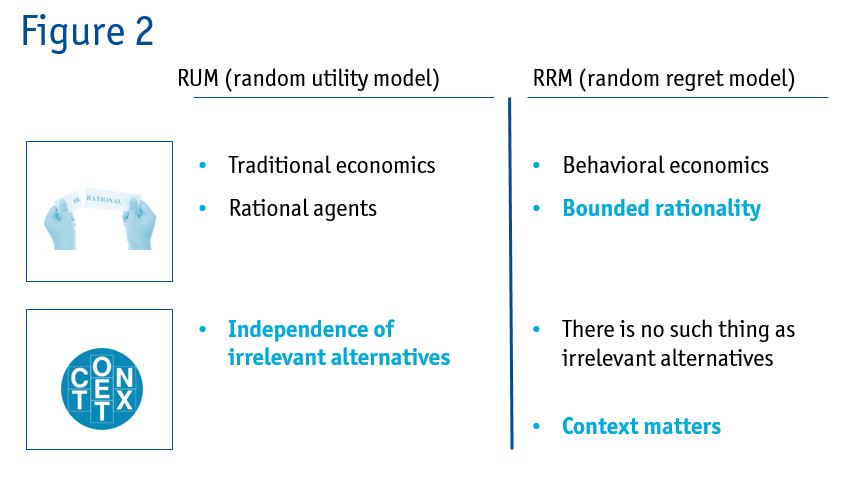
The most important differences between the two models are shown in Figure 2.
The hybrid solution
Both RUM and RRM have their pros and cons. The question is, which model brings us closest to reality? Do people base their choice on selecting the optimal combination of product characteristics or do they choose based on the desire to minimize the risk of regret? What would happen if we combine both principles? Would that give us the best of both worlds?
There are many reasons to stay with RUM coding, the current workhorse model for conjoint analysis. It is well-known. It works and it is well understood in the industry. However, RRM remains very interesting as a semi-compensatory model. Due to the compromise effect, RRM simulations can potentially outperform RUM simulations when there are product characteristics with intermediate scores for different levels. And last but not least, RRM takes the context of the selected product into account.
Because there are advantages in both models, why not use both at the same time? Would combining RUM and RRM improve predictive validity of the conjoint results?
Dual response none
Before exploring how this hybrid approach would work out in two case studies, SKIM researchers defined how to incorporate the concept of dual-response none since RRM is not possible if a “none” option is present (allowing a consumer to opt out of selecting a product by choosing “none of the above”).
With the hybrid solution it is possible to include a so-called dual-response none. Yet, one must code the dual-response none slightly different. We code each choice task with the dual-response none as two tasks. The first task is just the choice between the products (combining RUM and RRM), while the second task always consists of the chosen concept and a none parameter (RUM only). The assumption here is that the actual purchase decision is based on RUM and RRM does not have an impact. This idea is illustrated in Figure 3.

Case study: Health insurance
The structure of the data was as follows:
- four attributes (e.g., price) of which three are nominal (with 4, 3, 4, 5 levels);
- 15 choice tasks, all with three concepts;
- design strategy, and complete enumeration; and
- 1,245 respondents.
Researchers ran three separate models: RUM, RRM and the hybrid model. For the RUM coding they used part-worth and the RRM parameters were linear. In all runs they constrained the nominal attributes to follow logic order. In this study researchers compared RLH (root likelihood) and hit rate as shown in Figure 4.
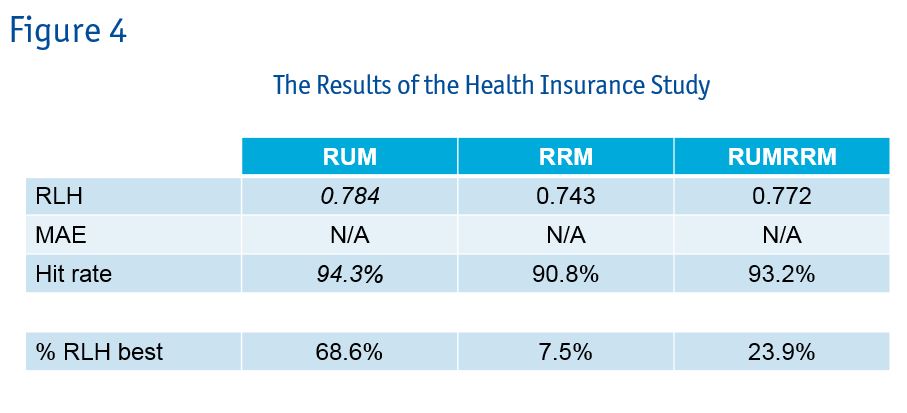
The percent RLH best, shown in Figure 4, is checking which RLH is best per respondent. RUM yielded the most winning RLH scores but looking at the other results, there’s no clear winner. The results are quite similar. The average correlation between the RLH scores across the three methods is 0.97.
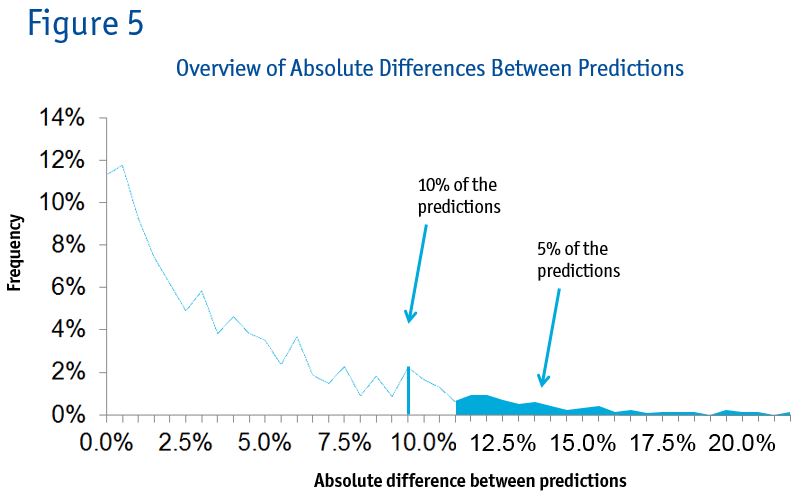
Digging deeper into the data found that although the first choice hit rates were similar, the predicted preference shares were not. The preference shares for each task of each respondent were compared. Considering the absolute difference between the predictions, 5 percent of the predictions were 11.5 percent or more off. Ten percent of the predictions were 9.5 percent off. This is illustrated in Figure 5.
In Figure 6 we show three examples of predicted shares, based on the three models.
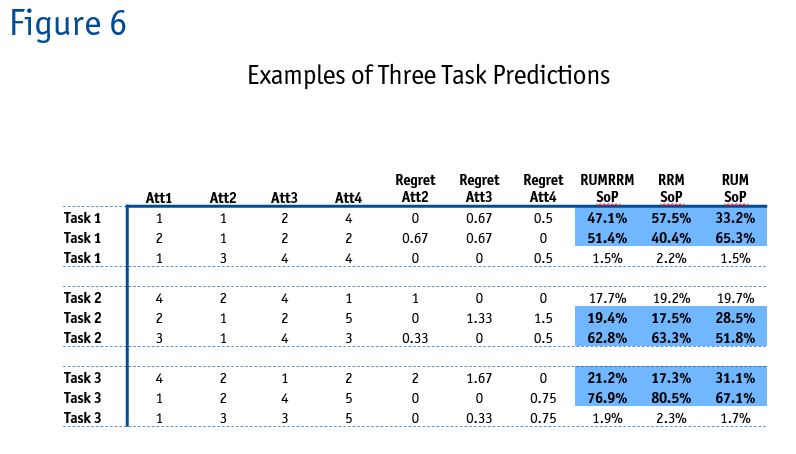
On Task 2, the first choice is predicted the same for all three models but a closer look reveals that there are large differences in shares and the rank order is not the same. The same data could potentially lead to different recommendations.
Case study: Tablets
The structure of the data was as follows:
- six attributes (e.g., RAM, camera quality, and price), of which five are nominal (with 5, 4, 4, 3, 5, 5 levels);
- 15 tasks, all with three concepts (three holdout tasks);
- design strategy, overlap; and
- a total of 1,247 respondents.
Nine hundred and thirty-one respondents answered 12 CBC tasks, plus three holdouts:
- Half of respondents received choice sets constructed with a minimum overlap.
- The other half of respondents had a design that allowed level overlap.
Three hundred and sixteen respondents answered 15 tasks, constructed at random, hence a lot of overlap. This cell served as a holdout for out-of-sample validity checks.
Here researchers also ran all three models. The results are shown in Figure 7.
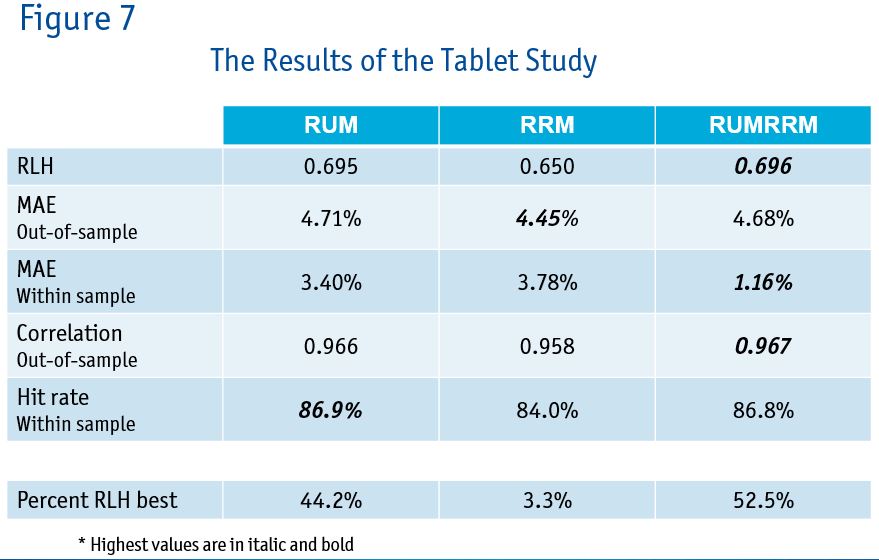
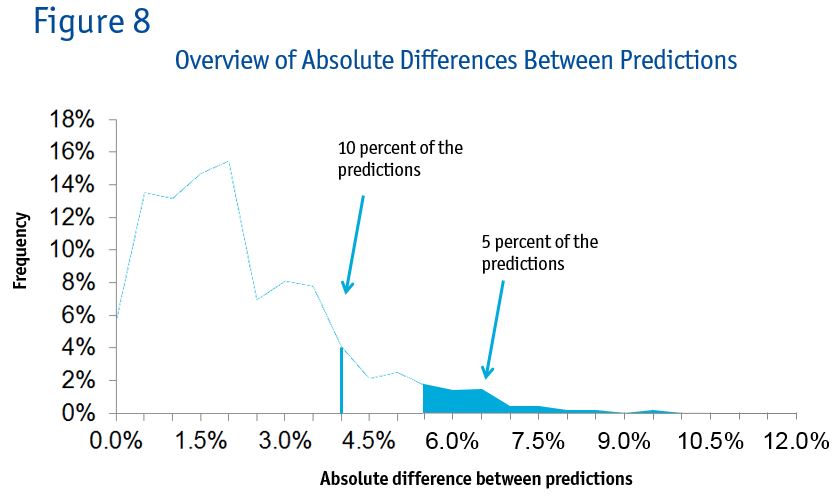
Again the results are quite similar. The average correlation across the three methods is 0.95. The same pattern occurs when we look at the absolute differences between predictions. In this case, 5 percent of the predictions were 6 percent or more off. Ten percent of the predictions were 4 percent off. This is illustrated in Figure 8.
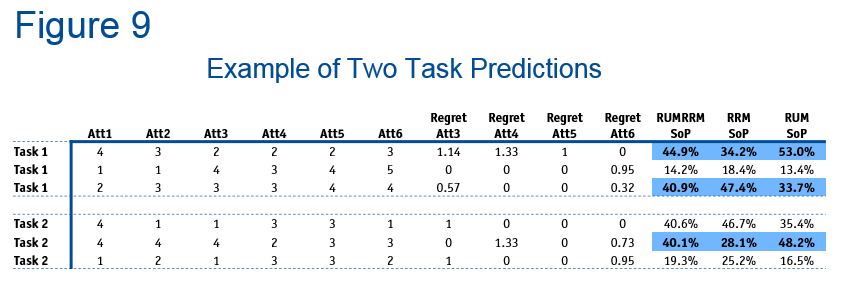
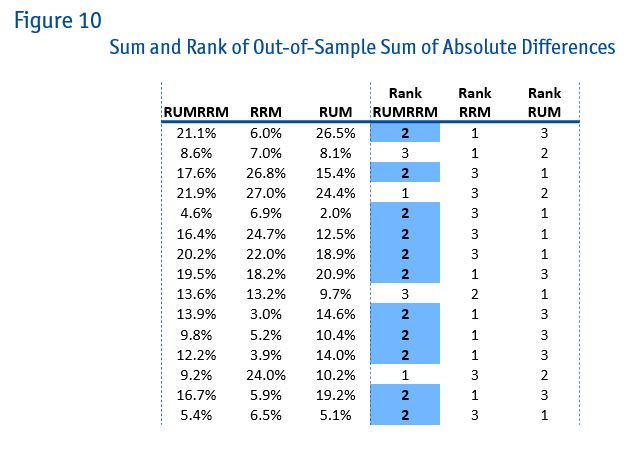
Here as well, the same data leads to different market leaders and different recommendations (Figure 9). Out-of-sample predictions are shown in Figure 10.
You can see that in most cases (73 percent), the hybrid model is the safest bet. In Dutch, this is called the golden middle road.
The hybrid approach
There are several reasons to favor this hybrid method. It offers the best of both worlds, while keeping the estimation process fairly easy:
- One can see and model the effect of context.
- The dual response “none” can be modelled.
- There is no need for new software because all can be modelled with standard software.
The result of the hybrid RUM/RRM approach is a similar predictive validity that takes into account how some consumers choose to maximize utility while others choose to avoid regret. The main advantage of combining both methods is that the results are less extreme, without knowing the true underlying decision tactics (maximizing utility or minimizing regret).
Simulations can show quite different results, leading to different recommendations for the research client, which is somewhat scary – or undesirable to say the least. Combining RUM/RRM seems to provide a balance between these RUM and RRM predictions, so it could be considered the safest bet.
References
Hardon, Jeroen and van der Wagt, Kees. “RUM and RRM – Improving the predictive validity of conjoint results?” Paper presented at the Sawtooth Software Conference, 2015.
Chrzan, Keith and Forkner, Jefferson. The Random Regret Minimizing Choice Modeling Paradigm: An Introduction with Empirical Tests. Sawtooth Software, Inc., 2014.
Sawtooth Software, Inc. CBC User Manual, Sequim: Sawtooth Software, The CBC/HB Module. Sawtooth Software, Inc., 1999.
Chorus, Caspar G. “A new model of random regret minimization.” European Journal of Transport and Infrastructure Research, 2010: 10:181-196.
Chorus, Caspar G. Random Regret-based Discrete Choice Modeling: A Tutorial. Springer Briefs in Business, 2012.
Chorus, Caspar G. “Random regret minimization: An overview of model properties and empirical evidence.” Transport Reviews, 2012: 32:75-92.