Editor's note: Kevin Gray is president of Cannon Gray LLC, a marketing science and analytics consultancy. This article appeared in the May 12, 2014, edition of Quirk's e-newsletter.
Meta-analysis is a set of procedures for statistically synthesizing the results of several primary studies. It is research on research and is used when we want examine the body of evidence about a topic, rather than relying on the results of a single study. Even in rigorous disciplines such as medicine, studies often do not agree in their central conclusions and meta-analysis provides a systematic way to examine a collection of results, typically effect sizes, across multiple primary studies. It also sheds light on factors potentially underlying dissimilarities in findings and helps us make sense of the patterns of effects. It began to take root in the '90s and is applied in medicine, ecology, psychology, education, business and other fields as well as for the evaluation of government programs. It is still quite new to marketing research and arguably underutilized.
Estimate the true size
Meta-analysis is increasingly employed in place of the traditional narrative literature review, which has been criticized by its detractors for being subjective, unsystematic and as "arithmetic with words." Meta-analysis is appropriate, provided the primary studies are not too disparate. Since real effects cannot be reliably established through one study alone, meta-analysis helps us better estimate the true size of effects and is better suited when we wish to generalize to a broad population.
Effect sizes are typically measured by means, proportions, risk ratios, odds ratios or correlations. However, meta-analysis is not simply a matter of adding up effect sizes in each study and dividing by the number of studies we are examining, nor is it just counting the number of significant differences favoring one hypothesis over another and choosing a winner. Instead, it uses statistical techniques to combine the results of multiple studies. Ideally, data from individual subjects (individual participant data) in each study would be used but more typically this is not obtainable and aggregate data must be analyzed instead.
Weighted by precision
In meta-analysis, the individual studies are weighted by precision, which is derived from the standard errors of the individual studies. The term "inverse variance" is often used to describe this weighting mechanism, which is primarily a function of sample size. Larger studies (i.e., those with larger sample sizes) will be more influential in meta-analysis. It is not necessary that all primary studies in a meta-analysis measure effect in the same way and formulas exist to convert among effect sizes based on dissimilar metrics. There are other methods besides the inverse variance scheme. For details, readers can refer to standard references such as Introduction to Meta-Analysis (Borenstein et al.) and Modern Epidemiology (Rothman et al.).
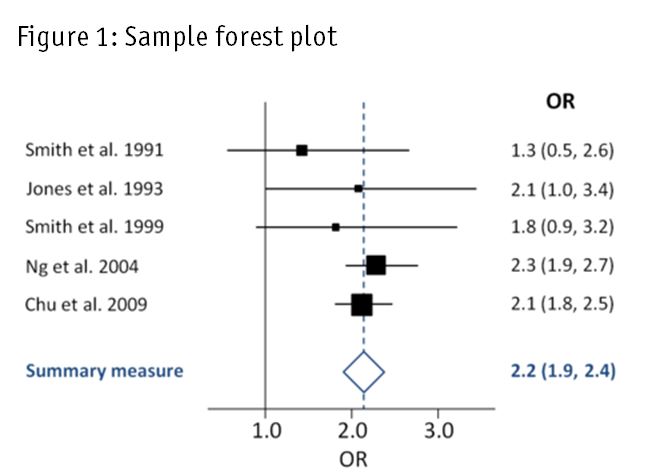
Forest plots
Results of meta-analyses are normally summarized with forest plots, a handy graphical device that efficiently conveys the highlights of the analysis. (Forest stands for "forest of lines" and we are interested in both the trees and the forest.)
Figure 1 shows a simple example, taken from Wikipedia, based on five studies. In practice, sometimes dozens or even hundreds of primary studies are used. In the plot, the size of a square is proportional to the corresponding study's weight in the meta-analysis and the horizontal line represents the confidence interval of the study's odds ratio (OR), an effect measure that is standard output from logistic regression and equals 1.0 when there is no effect. The diamond at the bottom of the plot reports an overall odds ratio of 2.2, with the real effect size estimated to lie between 1.9 and 2.4.

Variations of meta-analysis
Fixed-effect versus random-effects
Statisticians will be familiar with fixed-effects and random-effects models. In meta-analysis, fixed-effect (singular form) has a different meaning and Borenstein et al. suggest "common-effect" might be a more suitable term. The fixed-effect model assumes the true effect is the same in all studies and that differences we observe among studies are the result of sampling error, while random-effects models allow that the true effect may vary from study to study.
When fixed-effect models are used, studies with larger sample sizes will receive relatively more weight and smaller studies relatively less weight, though this by itself should not determine whether a fixed-effect or random-effects model is chosen. Confidence intervals under random-effects models will be wider because both within and between (across studies) sources of variation are taken into account. Random-effects meta-analysis tends to be preferred because the primary studies as a rule are heterogeneous in participant (i.e., respondent) characteristics, in the implementation of treatments themselves or in other important operational aspects. It is generally, though not always, more realistic to assume that the true effect could vary from one study to the next. A new method, the quality-effects model, has been advocated as an alternative to random-effects models.
Meta-regression
Regression is widely used in primary research and also has an important place in meta-analysis. Rather than subjects in a primary study, however, observations in the meta-regression data file are the results of the primary studies and both the dependent and independent variable(s) are at the study level, not the subject (i.e., respondent) level. As with standard regression, independent variables may be continuous, categorical or a combination of the two. Fixed- and random-effects models are both possible, as are variations of regression (e.g., polynomial). Analogous to regression in primary studies, the number of studies should be sufficiently large for the analysis to be meaningful and a minimum of 10 studies per independent variable is one rule of thumb, though this is not set in stone.
Psychometric meta-analysis
Any study has methodological faults that affect its results, sometimes substantially. Psychometric meta-analysis, also known as validity generalization or Hunter-Schmidt meta-analysis, attempts to adjust effect estimates for methodological limitations of the studies and perform a meta-analysis of the corrected results. The quality-effects model shares some of the aims of these methods.
Psychometric meta-analysis uses procedures based on psychometrics theory to make corrections for attenuation of effect size due to measurement error and other flaws. Effects will generally be larger and their variation smaller after corrections have been made and the distribution of true effects is emphasized, rather than the overall mean effect. Another distinction is that raw correlations are favored as the metric of effect and sample size is preferred for weighting.
Take into account
Researchers must take into account many factors when selecting primary studies. Obvious ones include the topic, the sample composition, how the sample was drawn and from what population and when and where the research was conducted. Less obvious, perhaps, are details of the study design (e.g., whether it was experimental or observational). (See my article, "Forget exact science: Drawing conclusions from observational research," in the July 22, 2013, edition of Quirk's e-newsletter, for an overview of experimental versus observational research.)
Other considerations include which potential confounders were accounted for, how they were measured, the analytic methods employed and, of course, whether sufficient information regarding the study has been published or can be obtained. To a degree, heterogeneity is desirable since we will have more confidence that the findings of the meta-analysis are generalizable to real-world circumstances, though this is not to say anything goes.
Publication bias is another concern. This is a complex topic but essentially refers to the fact that many studies go unpublished, not because of poor quality, but because no statistically-significant effects were detected. Effects that achieve statistical significance will, in general, be larger than those that have not. Publication bias reflects editorial decisions but researchers must first decide on their own whether to submit results for publication. Statistically-significant findings are also more likely to be published quickly, to be published more than once, to be cited frequently and to be published in English and thus easier to locate. Meta-analysis cannot not magically make these potential biases disappear but statistical methods have been developed (e.g., funnel plots) to help assess whether they are a serious problem in the set of studies we have tentatively selected. In short, judgment plays a large part in study selection but it must be remembered that science is not merely plugging numbers into formulas in mechanical fashion. Whatever approach we take and regardless of our topic, it's garbage in, garbage out.
Somewhat contentious
Despite having advantages over alternatives, meta-analysis remains somewhat contentious. There are several reasons for this. Because the combined sample sizes can be very large, very small effects can be depicted as significant, even when effect sizes in all the individual studies are not statistically different from zero. Larger studies, moreover, are often operationally more challenging and can actually be more error-prone than ones that are smaller-scale and more carefully supervised. But larger studies will have more weight in meta-analysis because of their bigger sample size. Also, as noted, inclusion criteria for primary studies will have a major impact on the results and another critique is that meta-analysis can make it easier for the investigator to "cook" the results by cherry-picking "ingredients" that support a favored hypothesis. In other words, it can be used for advocacy instead of science.
Proponents of meta-analysis often respond to criticisms such as these by admitting that many of them do indeed have merit but that they apply even more to traditional narrative literature reviews or simply counting significant differences (vote-counting). In meta-analysis, it is claimed that these dangers are more transparent. My own view is that, while properly-conducted meta-analyses have important benefits, we do need to be vigilant against potential malpractice, perhaps more so than in the case of narrative literature reviews, which, in my experience, tend to be circumspect in their conclusions.
Who cares?
To this point, meta-analysis has been little-used in marketing research and some might wonder "Who cares? I'm not a doctor or a psychologist, so why should I incorporate these methods into mine?" My first response would be that, as researchers, we need to be attentive to what researchers in other fields are doing. After all, nearly all our methods and research protocols have been borrowed from other disciplines!
At a more day-to-day level, marketing researchers often undertake desk research as part of a project, especially at the design phase, and when doing so may occasionally encounter meta-analyses. It is therefore helpful to have some background on what it is and its strengths and limitations. Furthermore, we can conduct it ourselves when designing new research. Lastly, we can use meta-analysis for R&D on new methodologies, for examining questionnaire design issues, in ROI analysis, in pricing research and for testing product claims, to name just a few.
In a tiny nutshell
The foregoing is meta-analysis in a tiny nutshell. For those who'd like to study it in depth, there are numerous online sources and papers in addition to textbooks. Experimental and Quasi-Experimental Designs for Generalized Causal Inference (Shadish et al.) is a widely-cited textbook that offers a comprehensive perspective on research, including meta-analysis, as well as detailed guidelines on research design and how it affects interpretation. The Cochrane Collaboration provides a very large repository of research on health care and health policy and is a good source for examples of meta-analysis. The Campbell Collaboration is a similar organization for social, behavioral and educational research.