
Editor's note: Nikki Aldeborgh is senior data scientist, Omer Ahmad is data scientist, Isidro De Loera Jr. is senior computer vision data scientist manager and Yuefeng Zhang is senior data scientist within global insights and analytics at McDonald’s.
In recent years a proliferation of internet-of-things devices, and an increased demand for real-time processing of data streams, has sparked interest in edge computing. Edge computing enables faster inference times than sending data to the cloud for analysis. Additionally, deep learning (DL) has made huge strides in domains such as vision, audio and text, making it an attractive candidate for data analysis and processing.
The problem arises, however, when trying to deploy computationally expensive DL applications in resource-constrained edge environments, particularly in a multi-tenant scenario where more than one DL model is running. For example, in autonomous driving systems it is essential to run multiple DL models such as classification, segmentation and detection. Furthermore, more than one of these applications often must be run concurrently, for example on different view angles (front, back, side) from the car. In the following sections we detail two avenues for optimizing performance in multi-tenant DL applications.
Multi-tenant GPU resource optimization
Co-locating multiple DL models on a single graphics processing unit (GPU) comes with some complexities that are not present, or are less extreme, in a single-tenant single-application scenario. Resource contention arises when multiple models are competing over the same memory and compute.
Memory constraints arise because models require a substantial amount of memory to store their weights, activations and input data. In the case where multiple models are deployed on a single GPU they all must compete for limited memory resources, which leads to slower performance and increased memory usage. Researchers have proposed various techniques to alleviate this, such as model quantization,1 weight pruning2 and knowledge distillation.3
Computational resource contention is another challenge for multi-tenant DL applications. Models can experience inter-tenant interference4 when executing concurrently on the same backend machine, which can cause latency degradation. This becomes worse with more co-located workloads and can degrade the overall application throughput. Thus, several service-level orchestration efforts have designed mechanisms for strategic co-location of DL models.5 A powerful tool offering many of these optimizations is Triton Inference Server, which we use for optimization of GPU resource usage.
Software-level model orchestration
Beyond the GPU memory, computing and scheduling considerations discussed above, the application itself needs to effectively orchestrate the flow of the data to manage hardware resources while ensuring optimal performance. To address this challenge, Python, a versatile programming language, offers a robust set of tools and paradigms for optimizing resource utilization. These tools include asynchronous processing using the asyncio interface, threading and queues. Each of these components plays a crucial role in orchestrating concurrent tasks for efficient data flow.
Unlocking multi-tenant potential
In multi-tenant environments, where multiple DL applications contend for shared resources, these techniques are promising. Triton Inference Server’s handling of resource contention, along with Python’s asynchronous processing, threads and queues, allow developers to design systems that effectively utilize available hardware while maintaining application responsiveness. By distributing tasks across asynchronous tasks or threads and managing data flow with queues, a harmonious ecosystem can be cultivated, ensuring that each tenant benefits from efficient resource usage without compromising system stability.
In the subsequent sections of this article we delve into the practical implementation of these techniques within the context of multi-tenant DL applications. We present a novel solution that enables deployment of multiple multi-tenant DL applications, each with a GUI component, on a Zotac with a single GPU.
The rest of the article is organized as follows: We provide a brief background on DL applications, edge computing and Triton Inference Server. Then we discuss the sample applications we use as a case study. Next we detail the proposed solution and finish with a detailed look at the results.
Background
Deep learning
DL is a subset of machine learning that utilizes multi-layer networks to learn and represent complex patterns in data, accomplishing tasks that were previously only thought to be possible by a human. One of the main drivers of DL’s growth has been the wealth of high-quality labeled data in the form of text, images and audio. Additionally, the availability of specialized hardware such as GPUs has made the training and inference speed of models fast enough for practical use. In our case study we focus on computer vision, a subset of DL that operates on imagery data. Specifically, our application performs object detection, human pose estimation and object tracking.
Object detection
Object detection is the process of identifying an object in an image and delineating it with a bounding box (Figure 1). Before DL came on the scene, object detection relied on classical machine learning techniques such as handcrafted features, but these struggled to deal with variations in lighting, pose and scale. Several DL-based approaches to object detection have since been developed and generally fall into one of two categories: region-based approaches and single-shot detectors. Region-based proposals such as Faster-RCNN6 first propose a region that looks like an “object” and then decide what the object is, using a classification algorithm. Single-shot detectors such as YOLO7 enable real-time object detection by combining the region proposal and classification into a single network.
Object detection is now ubiquitous, due in part to the DL approaches outlined above, the plethora of data available to train them and accelerated computing devices such as GPUs and tensor processing units. It is found in fields such as autonomous driving, medical imaging and augmented reality.

Human pose estimation
Human pose detection takes object detection a step further and delineates key anatomical keypoints from an image of a human, such as the head, hands, elbows, knees and feet. By discerning such information, human pose estimation (Figure 2) can reveal the precise posture of a human and, in the case of videos, the dynamics of their movement. There are several approaches to human pose estimation, most of which, like object detection, are based on convolutional neural networks. OpenPose8 uses part affinity fields to delineate human pose and YOLOv7-pose9 extends object detection to also detect keypoints.
Object tracking
Tracking applications seek to take detected objects and match them between frames of a video. They often use Kalman filters,10 which use an object’s current state to predict a future state and then match that prediction to the detected objects in the next frame using linear matching like the Hungarian11 or Jonker Volgenant12 algorithm. Furthermore, re-identification algorithms like DeepSORT13 use DL-based models to create a descriptive feature embedding of an object, which can be matched to feature embeddings in future frames. In a simpler case, a characteristic of the object being tracked may be used to track the given object, such as using shirt color to track a human. As long as the human is the only one wearing a certain color shirt, any frame where that shirt color is identified can be attributed to that specific human. This simply involves using a classifier such as ResNet14 to classify shirt color of the detected human.
Triton Inference Server
Triton Inference Server is an open-source deep learning framework developed by NVIDIA that helps mitigate memory and performance issues in a multi-tenant environment. Triton has several key features that reduce resource contention and optimize inference efficiency:
- GPU sharing and isolation: Triton supports GPU sharing, which allows multiple DL models to run simultaneously on the same GPU. This is achieved using GPU isolation mechanisms, which prevent models from interfering with one another. Triton logically separates each model’s memory and compute resources, ensuring one model does not impact performance of another.
- Dynamic batching: Triton uses dynamic batching to optimize GPU utilization. As inference requests come in, dynamic batching will group multiple requests together and process them as a batch, which is generally more efficient than running inference individually. This minimizes the overhead associated with launching GPU computations and improves the overall GPU utilization, reducing contention.
- Ensemble support: Triton's ensemble support gives the ability to group interdependent models together in a multi-tenant application. This ensures that the ensemble models are scheduled and executed together, thus reducing risk of contention between the related models. It also allows intermediate processing steps to occur on the GPU, reducing time spent converting tensors from GPU to CPU and back again.
- TensorRT integration: Triton Inference Server integrates with NVIDIA's TensorRT, which is an optimized deep learning inference library. TensorRT accelerates inference by leveraging the capabilities of NVIDIA GPUs and reducing the memory footprint of models through layer fusion and precision calibration.
- Latency-based scheduling: Triton uses latency-based scheduling to manage GPU resources effectively, prioritizing the most time-critical requests and minimizing inference wait times.
- Model instance management: Triton Inference Server efficiently manages multiple instances of the same model on a single GPU. Instead of loading the entire model into memory for each instance, it maintains a shared memory pool for common model components. This reduces the overall memory footprint, allowing more models to coexist on the GPU.
- Memory pools and buffer sharing: Triton Inference Server uses memory pools to optimize memory allocation for inference requests. It allocates a fixed-size buffer pool for each model to avoid the overhead of memory allocation and deallocation during inference. Furthermore, it leverages buffer sharing among different instances of the same model to minimize redundant memory consumption.
By employing these strategies, Triton Inference Server ensures efficient memory and performance management when deploying multiple models on a single GPU, making it a valuable tool for deploying deep learning models in production environments.
Python asynchronous processing
Asynchronous processing, generally powered by Python’s asyncio framework, introduces a paradigm where tasks can execute concurrently without blocking the main program's execution. This is particularly advantageous when using I/O-bound operations, in which case waiting for external resources can lead to inefficiencies. Asynchronous processing couples nicely with Triton Inference Server, whose gRPC client has an asyncio-compatible extension allowing other processes to continue while waiting on an inference request. By using asynchronous programming, we can ensure that the CPU remains engaged in productive work while waiting for I/O and Triton inference tasks to complete.
Python threads
Threads offer a means to achieve concurrency within a single process. Unlike asynchronous processing, which is more suited for I/O-bound tasks, threads are well-suited for CPU-bound operations. By leveraging threads, we can allocate separate threads to each application instance, allowing for parallel execution. This can be highly beneficial in multi-tenant deep learning applications, where tasks such as pre-processing, inferencing and user interactions can be managed simultaneously. Threading is compatible with most Python libraries, whereas few are asyncio-compatible, making the GUI development more straightforward in a threaded environment.
Queues: synchronized data exchange and communication
Queues provide a synchronized mechanism for transferring data between different threads or asynchronous tasks. As one task completes processing, it can add the data to the queue and the next task will receive it in a first-in, first-out order. In the context of multi-tenant deep learning applications, which demand efficient task distribution and data management, queues enable seamless coordination between tasks and threads, ensuring a smooth flow of data and maintaining responsiveness.
Application
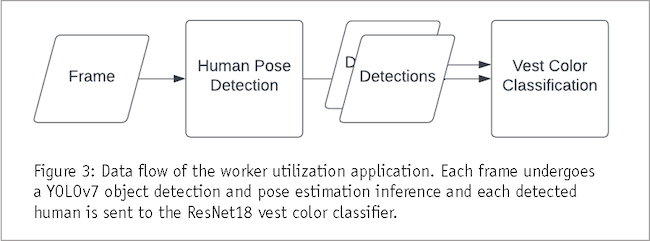
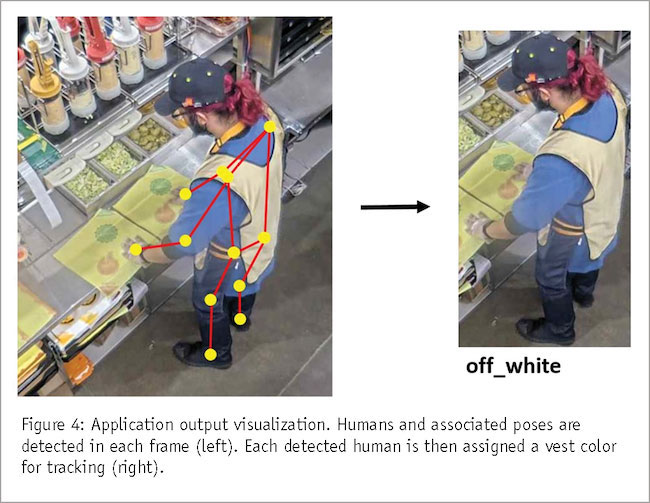
We implement a worker utilization application as a case study for our generalized multi-tenant deployment approach. This application has two DL-based components: human pose estimation to determine workstation activity status and subsequent tracking using a vest color classifier (Figure 3). There is a GUI component that visualizes the pose and assigned tracked worker ID in real time (Figure 4). This must be a highly performant application running at least five frames per second (FPS) for adequate responsiveness.
Workstation activity status
Our first deep learning application involves identifying all humans in each video and their associated poses. The pose of each person with respect to their user-delineated workstations will tell us if they are actively working at a station. If their hands or elbows intersect with their assigned workstation we consider that worker active.
Human tracking by vest color
Beyond establishing a person’s activity status at a workstation, we must ensure we are tracking the correct person for a given workstation. To do this we must assign an ID to each person detection and match it to detections in successive frames. There are multiple methods for re-identification between frames but we choose to have each worker wear a unique vest color and match detections based on the identified vest color. This only requires a small classifier as opposed to the larger and less reliable re-identification models like DeepSORT. For the vest color classification model we use ResNet18 on each detected human instance. The YOLOv7-Pose and ResNet18 classifier thus comprise a single instance of the multi-tenant DL application we seek to optimize.
Proposed solution
In this section we detail the system and software architecture of our solution.
System architecture
Our system (Figure 5) uses a Zotac with a Quadro P5000 GPU edge device connected to an IP camera angled at the people to track. The IP camera must be positioned properly as to see all humans of interest. The edge device receives all frames, runs the software and has a display output for the GUI.

Software architecture
In the pursuit of efficient and accurate multi-tenant DL solutions, our experiments explore various software configurations to harness the power of decoupled methods, ensemble strategies and different concurrency approaches. This section provides an overview of the software architecture underpinning our experimentation.
Decoupled method
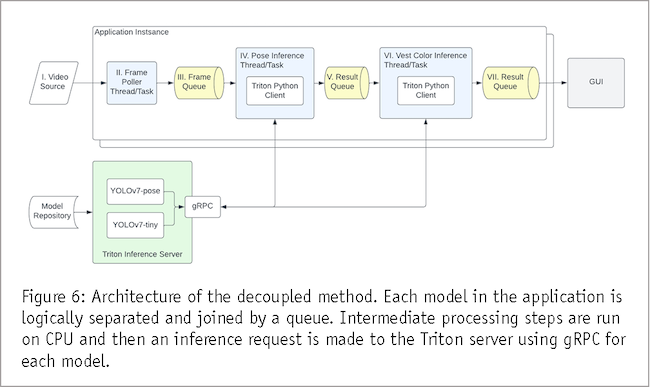
In the decoupled approach (Figure 6), each DL model is treated as a separate entity, operating independently and concurrently. The software architecture follows a modular design, where individual models are encapsulated within either Triton Inference Server or a PyTorch model runner thread. Input and output queues establish connections between each, ensuring seamless data flow. Models are offloaded from GPU to CPU after each step and perform all pre-/post-processing on CPU. This process can slow down the entire pipeline but it has the advantage of models upstream in the pipeline running inference on the next frame without waiting for more downstream tasks to complete.
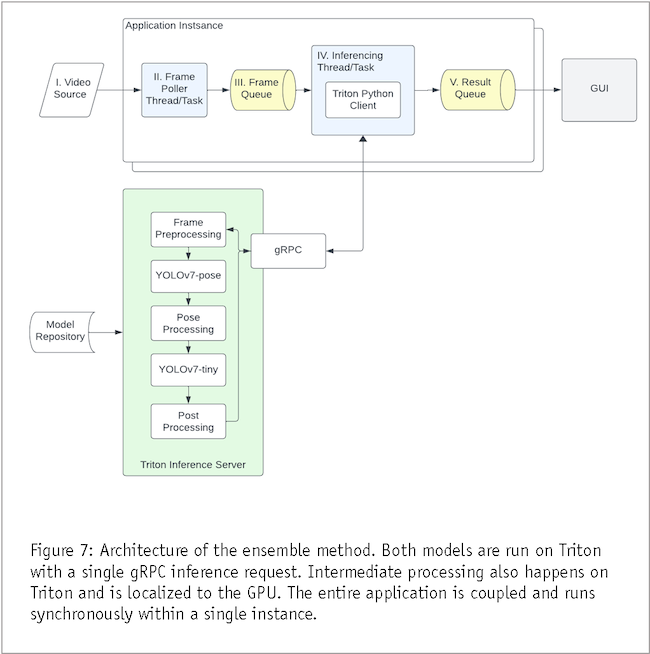
Ensemble method
The ensemble method (Figure 7) capitalizes on the power of model aggregation through Triton Inference Server. In this configuration, the ensemble of models is deployed onto the server, enabling centralized management. However, to optimize resource utilization, the pre-processing and post-processing steps remain localized on the GPU. This way only one inference task is run in the pipeline and tasks are run in serial for each application instance, unlike the decoupled approach.
Concurrency approaches
To further enhance performance, both the decoupled and ensemble architectures are configured with different concurrency approaches: threads and asynchronous tasks.
In the thread-based configuration, each model, or model ensemble, is run on a separate thread. This allows different models and application instances to run concurrently but due to Python’s Global Interpreter Lock (GIL), the Python interpreter will not run more than one thread in parallel, which could slow down the execution time.
Asynchronous processing, utilizing the power of asyncio, is employed to handle I/O-bound tasks efficiently and is not subject to the GIL. It also provides an event loop, which tracks the readiness state of different I/O events, thus avoiding switching costs of multithreading. The downside is that it is more complex to implement, particularly when it comes to designing the GUI.
Results
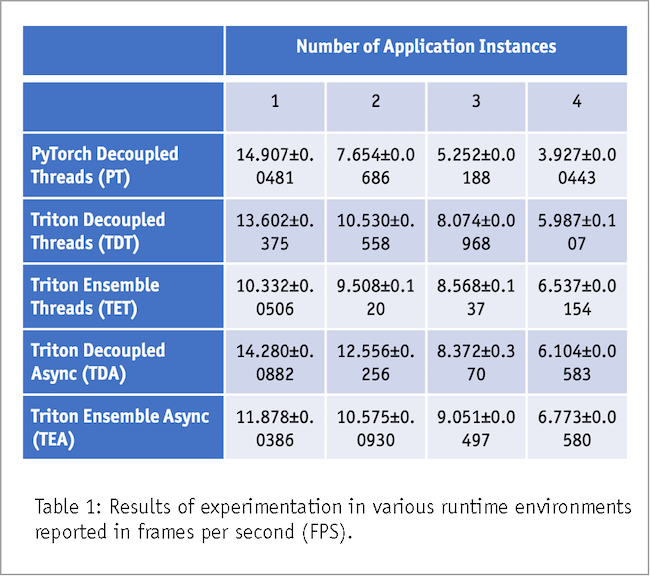
To optimize efficiency of our multi-tenant DL applications, we conduct a comprehensive series of experiments, exploring a number of runtime configurations to identify the most effective strategies. To gauge performance we use the metric of application frames per second (FPS). Our test environment involved running one to four instances of our multi-tenant worker utilization application, each trial extending for a consistent interval of 100 seconds. Numerical results are presented in Table 1. This section details our findings over the following runtime configurations.
Base case: PyTorch model with threaded model runners
We initiate our exploration by establishing a baseline performance metric using a PyTorch model without Triton for inferencing. This base configuration intentionally omits any proposed optimizations, allowing us to measure raw model performance. Notably, vanilla PyTorch does not have ensemble support or asyncio compatibility and is therefore only run using a decoupled, thread-based approach. It proves superior when only running a single application due to lack of operational overhead introduced with Triton. However, its performance deteriorates significantly as multiple instances are concurrently operated.
Triton decoupled experiments
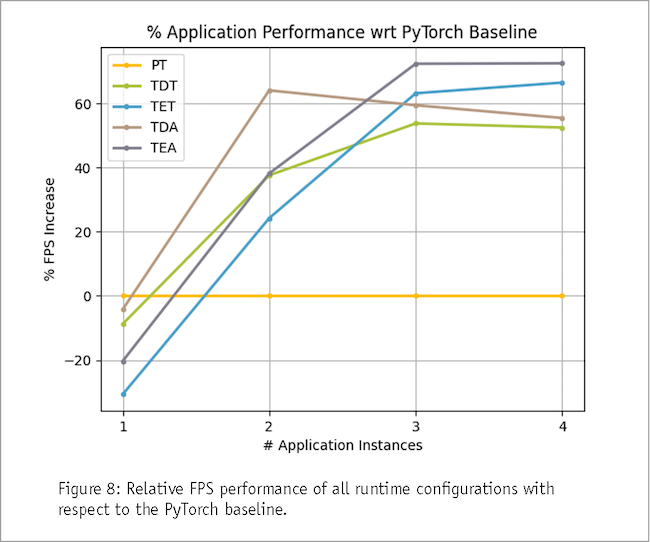
A distinct pattern emerges as we run Triton-based decoupled experiments. With two or fewer application instances running, the decoupled approach showcases its prowess, outperforming the ensemble configuration. The temporal gap between the upstream model (pose estimation) and downstream model (vest color classification) is responsible for bolstering performance, enabling the upstream model to begin processing the next frame while the downstream model is still processing the current frame. As a result, the decoupled approach, although slightly less effective than the PyTorch baseline with only one application running, gained momentum rapidly as the number of application instances increased. Particularly noteworthy is the Triton async decoupled approach, boasting a remarkable 64.044% performance enhancement compared to the baseline when two applications were run simultaneously.
Triton ensemble experiments
Transitioning to the ensemble architecture, we observed a shift in performance dynamics. The combined deployment of Triton Inference Server and ensemble architecture emerges as the optimal solution when more than two applications are running. As the number of worker utilization applications surpasses two instances, the models exhibited signs of saturation. The decoupled architecture's advantage of temporally separating model processing diminishes. Instead, retaining the intermediate processing steps on the GPU became the distinguishing factor. Here, the asynchronous application manifested a notable 72.473% performance boost compared to the baseline when all four applications operate concurrently.
Concurrency approaches
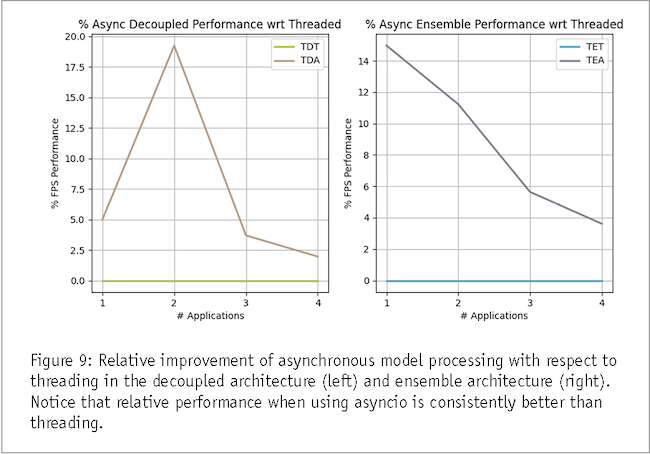
Finally, we seek to compare the effectiveness of concurrency approaches: threads and asynchronous processing using asyncio. Our findings conclusively demonstrate the supremacy of asynchronous processing, showcasing a consistent performance advantage across experiments. Notably, all asynchronous setups surpassed their threaded counterparts, with performance improvements ranging from 2% to an impressive 20%. These results underscore the innate efficiency and responsiveness embedded within asynchronous processing paradigms.
In this section we explored the multifaceted landscape of our multi-tenant multi-application DL experiments, unveiling the interplay of concurrency methods and architectural choices. The subsequent sections delve into the implications of our findings, shedding light on best practices for building high-performance multi-tenant deep learning applications.
Given valuable insights
In the dynamic realm of multi-tenant DL applications, our thorough exploration of various runtime configurations has given valuable insights into optimizing performance of such applications. We studied the interplay between decoupled and ensemble methods using Triton Inference Server and augmented these explorations into the choice of concurrency strategies. The results underscore the importance of tailoring runtime configurations to suit the unique characteristics of each application scenario.
Our investigations used PyTorch-based inferencing as a baseline for performance evaluation and was the optimal solution in a single-application environment. As more applications were run, however, Triton Inference Server emerged as a pivotal asset, enabling efficient orchestration of both the decoupled and ensemble methodologies. In a scenario where many inference requests are expected to saturate the application models, the amalgamation of Triton, the ensemble architecture and asynchronous processing is the optimal choice for runtime configuration. Retaining intermediate processing steps on the GPU is the critical determinant of performance. This approach delivers an impressive 72.437% performance boost when all four applications are running, when compared to baseline.
Finally, our exploration of concurrency approaches indicates the inherent efficiency of synchronous processing using Python’s asyncio. When contrasted with thread-based executions we see consistently superior performance ranging from 2% to an exceptional 20% improvement.
The symbiotic blend of ensemble and decoupled methodologies, in tandem with utilization of appropriate concurrency methodologies unveils a strategic roadmap for constructing responsive, efficient and high-performing multi-tenant DL applications. These findings offer navigation through the complexities of deploying real-time DL applications in an ever-changing field.
References
1 H. Wu, et al., “Integer quantization for deep learning inference: principles and empirical evaluation.” https://arxiv.org/abs/2004.09602, April 2020
2 M. Pasandi, et al., “Modeling of pruning techniques for deep neural networks simplification.” https://arxiv.org/abs/2001.04062, January 2020
3 G. Hinton, et al., “Distilling the knowledge in a neural network.” https://arxiv.org/abs/1503.02531, March 2015
4 D. Mendoza, et al., “Interference-aware scheduling for inference serving.” https://dl.acm.org/doi/10.1145/3437984.3458837, April 2021
5 F. Yu, et al., “A survey of multi-tenant deep learning inference on GPU.” https://arxiv.org/pdf/2203.09040.pdf, May 2022
6 S. Ren, et al., “Faster R-CNN: Towards real-time object detection with region proposal networks.” https://arxiv.org/abs/1506.01497, June 2015
7 J. Redmon, et al., “You only look once: unified, real-time object detection.” https://arxiv.org/abs/1506.02640, June 2015
8 Z. Cao, et al., “OpenPose: real-time multi-person 2d pose estimation using part affinity fields.” https://arxiv.org/abs/1812.08008, December 2018
9 C. Wang, et al., “YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors.” https://arxiv.org/abs/2207.02696, July 2022
10 R.E. Kalman, “A new approach to linear filtering and prediction problems.” https://www.cs.unc.edu/~welch/kalman/media/pdf/Kalman1960.pdf, March 1960
11 H.W. Kuhn, “The Hungarian method for the assignment problem.” https://onlinelibrary.wiley.com/doi/abs/10.1002/nav.3800020109, March 1955
12 R. Jonker and A. Volgenant, “A shortest augmenting path algorithm for dense and sparse linear assignment problems.” https://link.springer.com/article/10.1007/BF02278710, December 1987
13 N. Wojke, et al., “Simple online and realtime tracking with a deep association metric.” https://arxiv.org/abs/1703.07402, March 2017
14 K. He, et al., “Deep residual learning for image recognition.” https://arxiv.org/abs/1512.03385, December 2015