
Editor’s note: Alyona Medelyan is CEO of insights firm Thematic, Auckland, New Zealand.

Text analytics has been around for dozens of years and several hype cycles. The most recent one, in 2020, is attributed to GPT-3, a proprietary language model. It’s basically a giant black box that costs an estimated $12 million to train. A language model means that if you give it an input in natural language, it provides an output, such as a summary. Its summaries are impressive, but applications so far have been limited to toy projects rather than business use cases.
In market research and insights analytics, text analytics has been used to analyze free-text feedback and code responses to open-ended survey questions. Unfortunately, the technology itself has a bad reputation due to overpromising and under delivering. Many professionals still use Excel to manually code data, a tedious and (for many) unfulfilling task. And while it’s feasible on smaller data sets (50-100 responses), as we collect more and more data and seek statistically significant insights, this approach becomes unscalable.
So, I set out to find out why exactly text analytics has a bad reputation, and what an ideal solution should look like. After speaking to dozens of people who coded text by hand and tried out automation, here is what they disliked most:
- Transparency. Is the solution a black box? If so, it is hard to understand or tweak the results. And it’s impossible to trust the analysis.
- Flexibility. Is the solution rigid once it’s set up? If so, it won’t pick up unknown unknowns as they emerge in the data. Expects me to provide the code frame, which is half of the job,
- Set up and maintenance. How time-consuming is it to get started? If it takes too long to create training data, it will be impractical for smaller data sets. How easy is it to add more data and get results out? What kind of experts are required to maintain it?
After reviewing text analytics algorithms, I found that most approaches shared one or more of these drawbacks, as outlined in table below.
Approach | Transparency | Flexibility | Set up and Maintenance |
Manual Rules and Taxonomies | Transparent. Although can be difficult to tweak on larger data sets. | Cannot pick up unknown unknowns. | Requires professional services or dedicated personnel to maintain. |
Topic Modeling | Black box, most difficult to tweak and hard to interpret. | Flexible, can pick up unknown unknowns. | Easy to get the first output, but requires senior level data scientist to maintain effectively. |
Text Categorization | Somewhat transparent, but difficult to tweak if categories are similar. | It can take months to create training data. | Minimal maintenance, if categorization and data does not change. Otherwise, data scientists’ time to adjust to changes. |
It’s not a surprise that applying approaches taught in school results in mixed successes. Time has been ripe for a new approach, which can solve these drawbacks.
At the same time, some researchers started to work on theme detection algorithms – thematic analysis. It’s flexible instead of rigid and can pick up emerging themes in data. It’s self-supervised and doesn’t need training data or vocabularies. And with the right interface, it can be transparent to the user and even editable. It’s suitable for coding text feedback because it creates a code frame, or a taxonomy of themes directly from the data.
Let’s break down how it works.
Thematic analysis: How it works
Thematic analysis approaches extract themes from text, rather than categorizing text. In other words, it’s a bottom-up analysis.
Here’s an example:
Given a piece of feedback such as, “The flight attendant was helpful when I asked to set up a baby cot,” it would extract themes such as “flight attendant,” “flight attendant was helpful,” “helpful,” “asked to set up a baby cot” and “baby cot.”

These are all meaningful phrases that can potentially be insightful when analyzing the entire data set.
However, the most crucial step in a thematic analysis approach is merging phrases that are similar into themes and organizing them in a way that’s easy for people to review and edit.
This can be achieved in different ways, for example by using language models (similar to GPT-3). One option is to use word embeddings. However, don’t just use the pre-trained models. If such models are pre-trained on Wikipedia or Reddit, they won’t know the nuance of language. For example, they won’t know that “responsive” is the same as “fast” in the context of support. Make sure the models are purposely trained on millions of pieces of feedback, ideally feedback within the same industry.
Another language model can be used to group themes into a code frame (or a taxonomy). For example, here is how three people talk about the same thing and the resulting themes can group the results into themes and sub-themes:
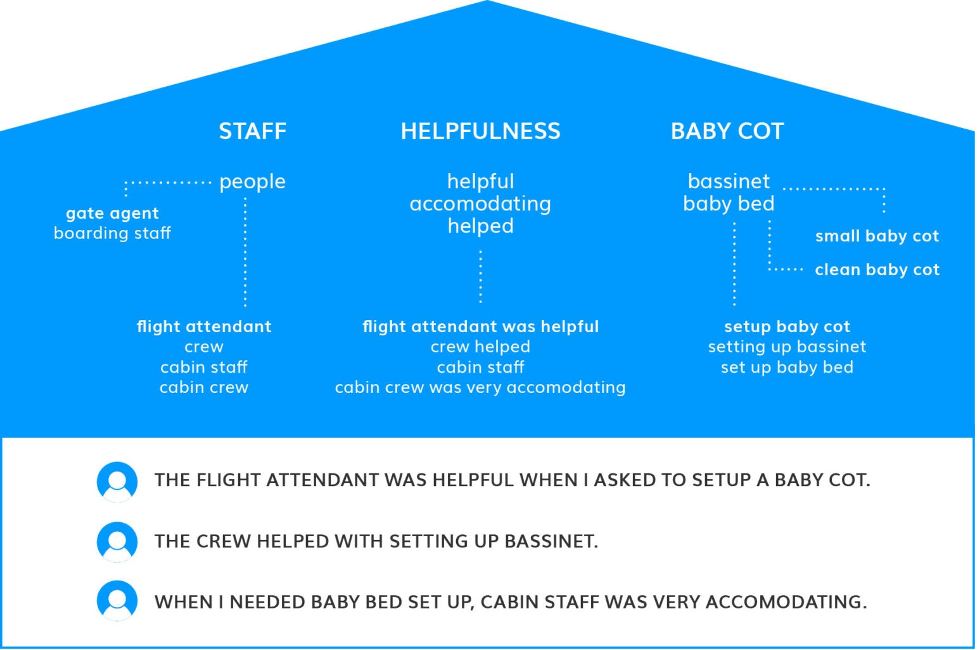
Advantages and disadvantages of thematic analysis
The advantage of thematic analysis is that this approach is unsupervised, meaning you don’t need to set up categories (code frames or buckets) in advance. To get started you just need the data. You can easily capture the “unknown unknowns.”
The disadvantage of this approach is that it is phrase-based. Sometimes phrases cannot capture the meaning correctly. For example, when there is a complex narrative, such as a piece of feedback saying: "It's the last time I'm calling you about this issue. No more!" This feedback indicates that the customer is likely to stop using the service, but capturing it is difficult.
In supervised categorization, you could train a model that could recognize this theme. But it is still tricky to build. Thematic analysis works well in 95% of feedback cases since most people try to be clear when they provide feedback.
For a data science team, thematic analysis can be difficult to implement from scratch. A perfect approach needs to not just discover, but also merge and organize themes, as well as discount irrelevant or generic themes. Ideally, the themes must capture at least 80% of feedback. Bonus points if the algorithm can handle complex negation clauses, e.g., “I did not think this was a good coffee.”
Human in the loop
Let’s be honest, no algorithm can produce 100% accurate results or 100% useful results.
We already looked at the example of “responsive support” vs. “fast support.” A model might miss that these phrases mean the same thing and belong to the same theme. So ideally, we need a person adjusting the results.
Theme groupings are also subjective by nature. For example, let’s say we found a theme “hard to find my size” in feedback from a clothing store. One analyst might want to group it under “range of sizes,” alongside other size related themes. Another person might want to group it under “store layout.”
Being able to quickly edit the results or change the groupings to suit your business better is critical. You need to be able to feed them back into the analysis if you want to achieve high accuracy.
Best applications of thematic analysis use the idea of a “learning loop” across their entire user database. You’ve encountered this concept when listening to music on Spotify or using Waze for recommended travel directions. The recommendations are powered by decisions of previous users. The more users use the system, the smarter it gets.
More companies are discovering thematic analysis because it can provide transparent and deep analysis – without data training or time spent crafting manual rules.