Less art, more science, please
Editor's note: Westley Ritz is director of analytics at TRC Market Research. He can be reached at writz@trchome.com.
“It’s part science and part art.” I suppose this appraisal can be applied to many areas but within traditional market research, it may as well be the unofficial slogan for segmentation analysis. A segmentation project is typically a large undertaking for a firm, with the goal of identifying unique groups of consumers to guide and support business decisions. The process is lengthy and has many stages, typically a mix of statistical techniques and practitioner intuition. This heavily blended science-and-art approach, particularly applied to the analysis itself, was prominent when I started my career 20 years ago and it still is. But should it be so?
Though not new, machine learning (ML) techniques are scientific approaches that have recently gained significant traction in market research. When applied to segmentation studies, these approaches can systematically replace dependency on researcher intuition. That’s not to say that genuine opportunities for artistic expression don’t exist in market research. Graphically representing data or creating engaging and thought-provoking survey instruments are a couple such examples. But when it comes to segmentation analysis, there are several instances where the process is labeled as “art” simply out of convenience, or more frankly, as an excuse for not having a better scientific approach. And in the absence of sound statistical methodology, an intuitive judgment is made.
 To start, consider the segmentation process as shown in Figure 1, here broken into three parts: 1) identifying the project scope and related dimensions to test; 2) analysis and formulation of segments; and 3) presenting and distributing the resulting segments for company adoption.
To start, consider the segmentation process as shown in Figure 1, here broken into three parts: 1) identifying the project scope and related dimensions to test; 2) analysis and formulation of segments; and 3) presenting and distributing the resulting segments for company adoption.
The initial phase of a segmentation project is admittedly highly artistic. The goal is to establish the dimensions or themes that should inform and differentiate the segments, which is done by understanding the objectives, purpose and intended use of the project results. Instead of analysis, this stage is ripe with discussions, interviews, interpreting what is known and unearthing what is unknown. Researchers may hold brainstorming sessions, conduct stakeholder interviews, review past research, examine known company and industry metrics or conduct qualitative research. And upon thoughtfully determining these dimensions, the task of capturing the necessary information may proceed.
And, skipping to the last phase, the derived segments are brought to life through art. The metrics and mean values that describe each segment are transformed into plain-English descriptions. Personas to represent each segment are built for executives to relate to and quickly grasp how they may or may not reach that consumer. And action plans are distributed to company departments with direction for implementation on how to engage with consumers based on those personas.
Unlike the front and back ends of segmentation, which are rightfully artistic, the middle stage of analysis and segment formation is ripe for scientific methods. However, researchers may not be taking advantage of all the techniques at their disposal, which would reduce the need for human intervention and result in better outcomes. Here are a few specific instances from the analysis phase that are commonly labeled as artistic:
Arbitrarily removing or adding variables upon review of the initial segmentation output and rerunning the analysis until an acceptable solution is found.
Subjectively picking a single solution from many options after running the analysis multiple times via various methods and number of clusters.
Actively tailoring a predictive algorithm for classifying outside respondents (aka typing tool) to ensure the so-called opportunity segments have a high degree of accuracy, often at a cost of sacrificing the accuracy of the other segments.
While the above attempts may ultimately yield an acceptable solution, chances are it’s suboptimal and certainly is inefficient. And the reality is that superior scientific approaches do exist. With the rise in popularity of ML techniques, due to increased computational power, accessibility and awareness, these methods can and should take a larger role in analytical processes. To demonstrate the advantages of applying these methodological procedures, the remainder of this article looks at three different phases of a typical segmentation process:
- variable selection for analysis;
- performing the segmentation analysis; and
- creating a predictive algorithm for typing future respondents
Variable selection
The old adage “Garbage in, garbage out” couldn’t be truer than when applied to segmentation. Poorly chosen or improperly coded variables will ruin any chance of developing useful results. What is required for successful implementation has been well-documented: low redundancy or low multicollinearity,1 a high degree of discrimination or variability, and variables which are actionable and represent dimensions we desire the segments be built around. As mentioned, only that last piece is art since it requires careful collaboration and discussion with the client to identify the proper variable dimensions for consideration. The rest, all science.
Thankfully, there’s no longer any need to guess at variables, run the analysis and then iteratively remove or include variables based on the outcome (low differentiation or unidimensional segments). Rather, there are methodologies to discern both unique and discriminating variables prior to segmentation. Two popular R packages for variable selection are clustvarsel2 for continuous variables and the VarSelLCM3 package for a mixture of continuous and categorical data types. Both are model-based approaches, utilizing information criterion statistics, to determine the optimal selection of variables. As depicted in Figure 2, these models use the proposed segmentation variables (the initially defined dimensions) as input, and upon specifying a threshold, they efficiently output the ideal variables to take forward into analysis.
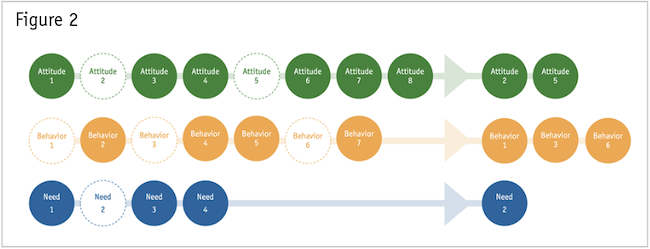
Segmentation methodology
After rigorously extracting a quality set of variables to proceed with in analysis, now is not the time to let up on the scientific process. And so, gone are the days of running multiple solutions via different techniques and choosing the solution that simply “reads” the best. Sure, different applications will result in different outputs but we should be harnessing that reality, not being bullied by it. While admittedly there isn’t a one-size-fits-all solution to every project, ensemble methods are an effective approach well-suited for many segmentation applications in market research.
Ensemble techniques are popular in ML, with the ability to be applied to many different methodologies. In regard to segmentation, ensemble analysis takes as input the classifications of many segment solutions. These are produced via varying procedures and include different numbers of clusters. (While the example in Table 1 depicts only three solutions, in practice this number will be much higher, closer to 40 or more.) Then the ensemble looks to cluster across them all to reveal a consensus solution, one that is more stable, reproducible and leads to higher prediction accuracy. And as a bonus, the process is also more efficient as time isn’t spent sifting through many solutions and attempting to pick the one that feels best. While several applications exist, an open-source option is the R package diceR.4 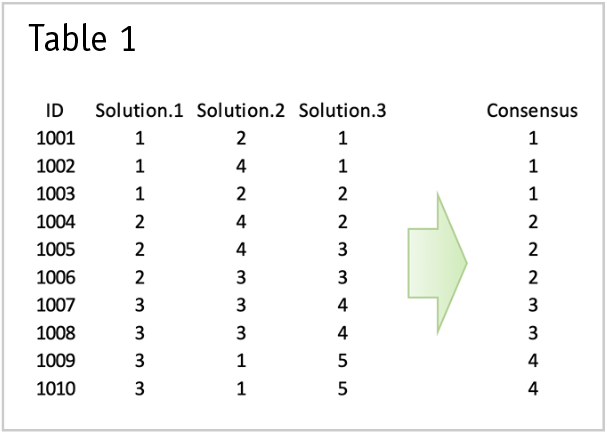
Typing tools
The crux of market research centers around causal inference, understanding the “how” and “why” to guide business decision-making. And the technical approaches outlined so far put researchers in the best position to elicit these crucial insights. But as part of making a segmentation analysis actionable, future consumers need to be classified into the established segments to guide messaging, sales and general interaction. Therefore the main goal of algorithmic typing tools is prediction accuracy.
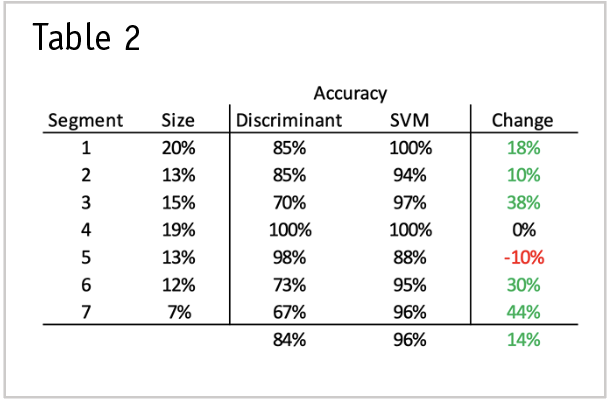
Traditional approaches to typing respondents, such as discriminant analysis or rule-based heuristics, suffer from a lack of generalization, making them unreliable and inaccurate once you test beyond the source dataset. And often, the researcher is left manually iterating subsets of variables to reveal an acceptable solution. Instead, ML techniques were developed to overcome these issues. Table 2 shows an example from a segmentation in the online instant delivery industry, comparing the accuracy of discriminant analysis against an ML technique called a support vector machine (SVM). Note in five of the seven segments, the accuracy of predicting which segment holdout respondents belonged to increased 10% - 44%, and the overall accuracy increased 14%.
 In fact, even more-accurate models could be developed via deep learning ML algorithms utilizing neural networks but they are usually impractical for our purposes. Neural nets, while powerful, don’t lend themselves to a plug-and-play application due to their complexity. And typing tools are just that, a deliverable tool that anyone can utilize. Simply plug in the responses of a new respondent and the result is a prediction of which group they belong to. So instead, shallow-learning algorithms like SVM are recommended because they are still highly accurate and also perform well as a deliverable tool (programmed in Excel for example). SVM models are available via the svm function in the R package e10715 or through a few different Python libraries.
In fact, even more-accurate models could be developed via deep learning ML algorithms utilizing neural networks but they are usually impractical for our purposes. Neural nets, while powerful, don’t lend themselves to a plug-and-play application due to their complexity. And typing tools are just that, a deliverable tool that anyone can utilize. Simply plug in the responses of a new respondent and the result is a prediction of which group they belong to. So instead, shallow-learning algorithms like SVM are recommended because they are still highly accurate and also perform well as a deliverable tool (programmed in Excel for example). SVM models are available via the svm function in the R package e10715 or through a few different Python libraries.
Less guesswork, more confidence
There will always be a need for art (creativity and thoughtfulness) in the market research profession. As demonstrated here, utilization of the soft sciences and artistic expression is essential for brainstorming and communication. But when it comes to data analysis, it shouldn’t be the fallback or catch-all when quality data-driven methods are at our disposal. Instead, embrace ML to tease the most out of the data, allowing science to play a prominent role in supporting derived business decisions and recommendations. There will be less guesswork in the process, more confidence in the output and greater value provided to clients.
References
1 Sambandam, Rajan. (2003). “Cluster analysis gets complicated.” Marketing Research. 15. 16-21. Also: https://trcmarketresearch.com/whitepaper/cluster-analysis-gets-complicated
2 clustvarsel, https://cran.r-project.org/web/packages/clustvarsel/clustvarsel.pdf
3 VarSelLCM, https://cran.r-project.org/web/packages/VarSelLCM/VarSelLCM.pdf
4 diceR, https://cran.r-project.org/web/packages/diceR/diceR.pdf
5 e1071, https://cran.r-project.org/web/packages/e1071/e1071.pdf