Editor’s note: Pete Cape is global knowledge director in the London office of Survey Sampling International.
Survey routers in online research work like routers in telephone units. A router in a telephone unit directs a potentially willing respondent to an available interviewer who then administers an interview. In the online research world, the router directs a willing respondent to an available open survey.
Using a router in an online survey enhances both efficiency and the respondent experience. The chance of the respondent’s willingness to participate being met with a screen-out or a “Quota full” message is greatly reduced. The negative impact that rejection has on a panelist when he or she is ready to do an interview cannot be overestimated. Respondents resent giving their time and effort only to end up screening out of surveys. Screen-outs are, in many panelists’ eyes, the No. 1 cause of dissatisfaction with the survey-taking process.
While using a router can decrease the incidence of screen-outs, it can also inject bias. Since respondents usually only can complete one interview, they are being systematically excluded from all other interviews for which they could qualify. Systematic exclusion is a bias.
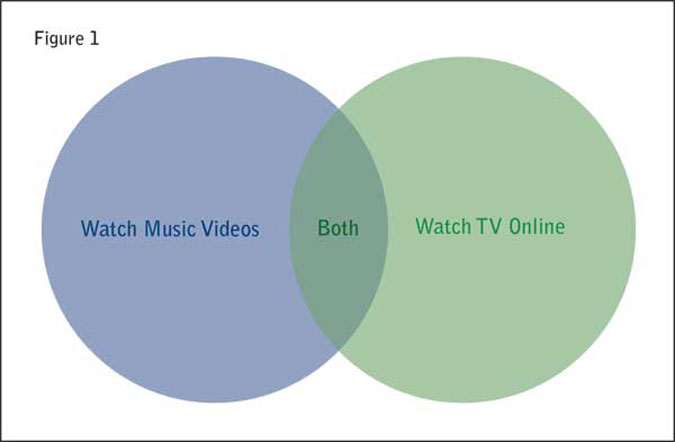
At the 2010 CASRO panel conference in February, Olivier de Gaudemar and Scott Porter of OTX illustrated the bias engendered by routers through use of Venn diagrams. De Gaudemar and Porter cited two studies: one looking for people who watch music videos and the other looking for people who watch TV online. Naturally, there are some people who do both (Figure 1).
The impact of the bias on one survey or another will depend on the router design. A purely random router will assign people who do both roughly equally between the two surveys, as shown in Figure 2.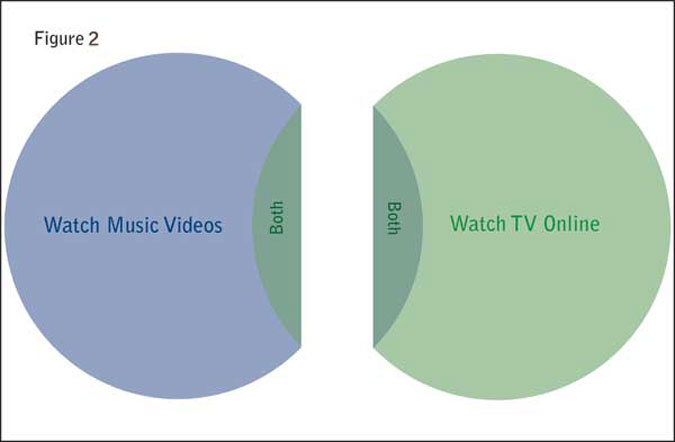
A priority router will assign people who do both to one survey in preference over another (Figure 3).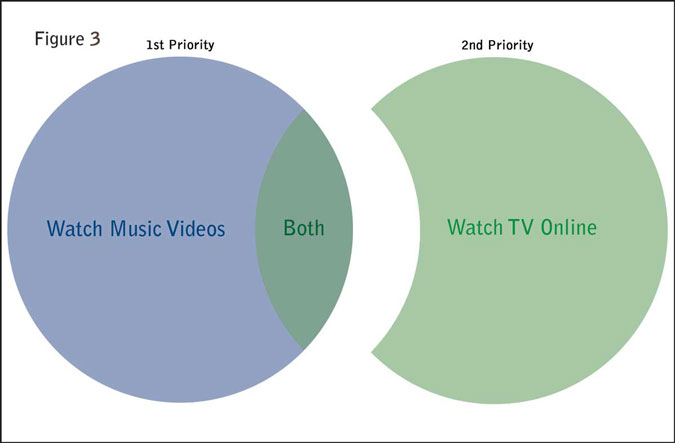
Note that the size of the overlap will impact the bias as will the relative sizes of the two projects. More typically there will be multiple projects of varying sizes running at different times with varying degrees of overlap. Changes to priority order and any random elements within the router design make it unlikely that the sample will have a nice crescent shape as in the two-survey scenario. A sample suffering bias may actually look more like the one shown in Figure 4. 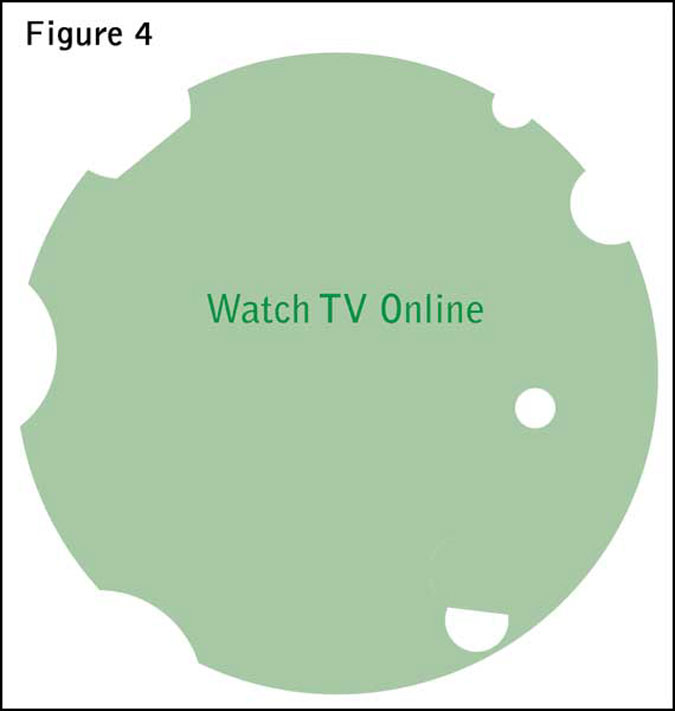
Small nibbles and holes appear in the sample where particular types of people have been selected for other surveys when they could have qualified for the “watch TV online” study.
Researchers have always stressed the need to minimize the risk arising from systematic errors (i.e., bias). Reducing or eliminating the risk was important when bias could not be measured. In the example here, the size of the bias can be measured since the size of “both” is known at the top level of the router. It can be corrected for through weighting, assuming a priority system hasn’t been utilized that has resulted in a situation where, for example, there are no “both” people in the “watch TV online” survey to weight.
Must be different
A secondary consideration must be whether it matters. Two elements will come into play. Firstly the size of any hole or nibble needs to be considered. If, for example, only 5 percent of the potential sample is missing from the actual sample, is it possible for the missing 5 percent to affect materially the outcome of the survey? For the bias to have an effect on the outcome of the survey, the hole must be big and the people missing must be different from those who are present. Technically speaking, the bias must be correlated strongly with the subject matter of the questionnaire. Imagine a survey subject where men and women thought alike on each and every question. At this point it would not matter if the entire sample was made up of women, because the survey results would be exactly the same.
This may strike some researchers, used to balancing samples on gender as a matter of course, as somewhat odd. Think instead about some variable we do not balance on as a matter of course, say left- or right-handedness. If left- or right-handedness does not affect the answers to the survey then there is no need to ensure a “correct” balance and no need to be concerned if there are no left-handed people in the survey. In these two examples gender and handedness are equally of no consequence to the project. Researchers may feel some discomfort at the thought of the bias in the case of gender but probably less so in the case of handedness. This is a result of what they are accustomed to rather than because it matters.
A simulation
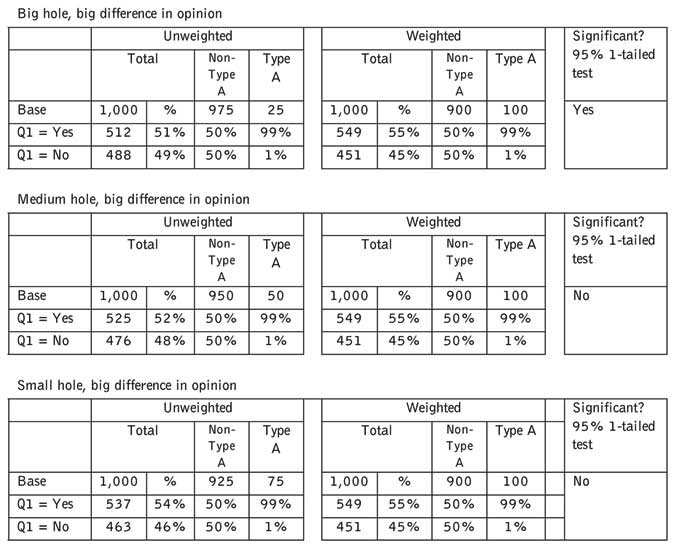
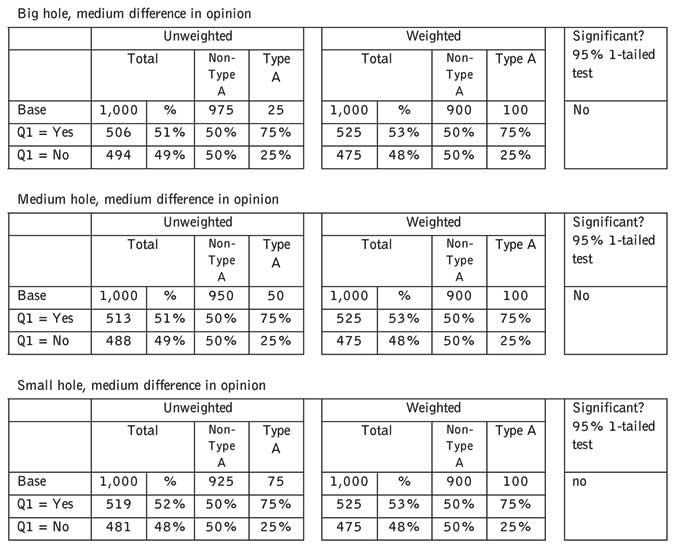
The effect (or lack of effect) of bias can be demonstrated through a simulation. In each of the accompanying tables, we adjust the number of Type A people in the sample. Type A people are the hole in the sample. We also adjust the extent to which they differ in their views from everyone else. In all cases, the natural proportion of Type A people in the population is 10 percent. We are weighting to, in effect, this natural proportion. We have fixed the opinion of non-Type A people as 50:50 on the question at hand to keep the number of dimensions under some control.
In only one case in our simulation does the correction for the hole make a statistically significant difference to survey results. Even then, the results change from 51 percent to 55 percent. Few researchers would generally make much of a difference of that magnitude.
To have made a significant difference, the missing respondents would have had to be a large proportion (7.5 percent) and radically different in their views on the subject.
This simulation is for a two-project scenario since this is easiest to comprehend. The two-project scenario is, in fact, the scenario with the greatest potential for bias. Every time a new project is added to the mix, and assuming some random element in the assignment process, the effects are diluted.
Not discernable
Survey Sampling International (SSI) tested 39 projects concurrently, all of which had run in the past, and examined data distributions not for the bias itself but for the effect of the bias on the data. In the majority of instances (27) data differences were not discernable. Of the 12 remaining projects, either a logical reason for the change was found or we were able to demonstrate that it was not bias arising from survey allocation that was responsible for the data difference.
This last point is interesting. Because the router operator should be aware of all the surveys any one respondent could have taken, as well as which one actually was taken, they know how the sample ought to be distributed across all the screening questions. This gives the opportunity to weight the data set to this distribution to see how the data might be affected.
This is not the case when the precise same bias arises from panel management practices. Panel owners often know a great deal about their panelists and do not want to overburden them with invitations. Assume a sample of BMW owners is drawn from the panel to take part in a survey. At this point they are not available to take part in any other survey. All the other surveys that the panel company is running will be biased through the systematic exclusion of BMW drivers. Precisely the same bias occurs in the router. This will not be transparent to the client nor is it likely that the client’s survey will ask about automobile ownership. No correction can be made to the bias.
Without panel management rules, the bias occurs when the panelist selects which of his or her many e-mail invitations to answer. Again there may be some systematic, rather than random, selection procedure going on regarding the incentive, survey topic or interview length, for example. The point is that it is both possible and unknown.
The comparison chart summarizes many of the biases inherent across methodologies. 
No evidence
It is incontrovertible that routers bring bias to online research. As can be seen in the comparison chart, however, bias is inherent in telephone surveys, in online surveys with direct invites and in online surveys using a router. The real consideration is whether the bias introduced by a router in online research is worse than the bias introduced using a direct invite and if the bias materially affects the survey outcome. SSI’s research suggests that a router does not make the current situation worse. There is no evidence that the bias materially affects the outcome of the survey. Furthermore, using a router in online surveys actually improves the respondent experience. And in today’s online environment of increased competition for people’s time and attention, this may be the most important consideration of all.