
When does good data go bad?
Editor's note: Rasto Ivanic is founder and CEO of GroupSolver. He can be reached at ivanic@groupsolver.com.
Are surveys that require humans to answer researchers’ questions still necessary? Do the expense and time commitments needed to execute traditional market research justify the value that survey research provides? Or is gen AI technology at the point where traditional survey research can be replaced by cheaper and quicker querying of synthetic panels? This article explores the economics of the two alternatives. It offers a framework and a few rules of thumb for researchers who may be considering which option is more appropriate for their specific use case.
We propose that the economics of a reliable synthetic (aka gen AI) panel depend on a few key factors: the accuracy of the initial panel training; the decay of the panel's accuracy as the world around it changes over time; and the number of ad hoc surveys the synthetic panel replaces.
Connect with consumer preferences
The success or failure of industry innovators, marketers or product designers ultimately depends on their ability to connect with consumer preferences. Unsurprisingly, they rely on many tools and techniques to uncover and understand consumer decision-making preferences before committing millions of dollars to market a product.
Synthetic panels and AI-generated virtual avatars are a new approach to understanding consumer preferences. Trained on human data to answer customer insight questions, they offer flexible and near-instantaneous access to virtual consumers with the promise of helping researchers receive answers to their questions faster and potentially more cost-effectively than traditional ad hoc panels, focus groups or live interviews. The ability of synthetic panels to mimic human consumer responses is rapidly developing and it is expected that their prediction accuracy will continue to approach that of human panels.
However, innovative marketers and product designers do not develop new products in static environments. Consumer preferences change over time, sometimes frequently and often unpredictably. The benefit of conducting market research with human respondents is that temporal changes in consumer preferences are embedded in every new batch of collected data. Alternatively, data collected from a synthetic panel trained on human data at a prior point will eventually become obsolete unless the synthetic panel is continually trained and re-trained over time.
The purpose of this article is not to argue for or against the merit of synthetic panel data as a research method. Instead, it offers a framework for marketers and researchers to think through their decisions to invest in synthetic panels versus conducting ad hoc human surveys.
Why synthetic respondents matter
Synthetic panels offer a substantial opportunity to simulate data that would normally need to be collected – often at great cost – from surveys and in-person interviews. Intelligent synthetic panels thus offer an opportunity for researchers to ask follow-up questions and test hypotheses that evolve dynamically. This technology is particularly useful when human respondents are difficult or expensive to reach on topics closely related to the data sets used to train the synthetic panels.
The costs of constructing well-trained synthetic panels are not trivial. Even when data processing is fully automated, recruiting and compensating human subject-matter experts needed to train a synthetic panel can cost anywhere from $20-$50 per recruit for a general-population panel and $200 or more per recruit for B2B respondents or other highly specialized panels. This makes building a synthetic panel that can answer questions beyond a trivial ChatGPT inquiry a sizeable investment of thousands, if not tens of thousands, of dollars.
Therefore, market researchers should carefully consider the return on their investment, understanding that there are alternative approaches to collecting data, such as surveys, interviews or other primary research methods. These alternatives, however, have the disadvantage of delivering insights one time only and do not lead to creating a productive asset (synthetic panel) that can continue to answer questions and provide insights more than once.
To make an informed decision, we introduce a framework that could help decision-makers determine which of the two approaches may be a better investment of their customer insights dollars: building a robust synthetic panel (an asset) or commissioning human-only market research (an expense) when and as needed. Framing the two alternatives as a one-time investment into an asset versus a series of expenses over time allows us to apply a simple decision-making framework to determine which strategy offers a greater economic benefit to the business.
Understand underlying drivers
Before discussing economic returns, we should understand the underlying drivers of value for market research and, by extension, the value of a synthetic panel or an ad hoc survey. In market research, we ask customers questions to understand their preferences and make accurate predictions about their future behavior. We often plan to invest significant resources into making a product a market success and asking smart questions of consumers is a way to hedge our bets and de-risk our decisions.
Prediction accuracy, or being able to rely on model data and the stories it tells, is the main objective of any market research we do – whether with human or synthetic respondents. If we believe that a synthetic panel is an investment, it should continue to have value and deliver precise predictions over time and, ideally, the investment into it should be no greater than the aggregate value it produces over its multiple uses until it becomes obsolete. In that respect, synthetic panels can be thought of as any physical or financial asset. A bridge built a hundred years ago may have lost its value and function and need to be replaced even if it was meticulously maintained. Financial investment needs to produce risk-adjusted interest over time greater than the inflation rate during that period or it will become less valuable as time passes. Synthetic panels, we argue, behave much like other assets with their present value decreasing over time. At a minimum, the cost of building and maintaining a synthetic panel should be lower than the total cost of all ad hoc surveys that would have been conducted in the absence of the synthetic panel asset.
Therefore, we propose that the decay of accuracy of any synthetic panel should be considered when investing in it, much like we consider material decay over time before building a bridge or an inflation expectation before acquiring a financial asset.
Before discussing training accuracy decay, let’s first talk about the other key driver of the synthetic panel’s return on investment: its initial training accuracy. Just like a bridge is at its best right after it is built, its “best” may or may not be good enough to pass the initial inspection and allow cars to drive on it. Park et al.1 show that a well-constructed general synthetic panel can be quite accurate relative to the answers obtained from its human “trainers.” The accuracy of a synthetic panel, however, is not guaranteed to be high for all panels equally. Using a synthetic panel to answer questions about pulmonary disease diagnoses will not perform well relative to answers given by pulmonologists if the synthetic panel was constructed from a general population that knows nothing about how lungs function.
Initial training accuracy – or the match of the synthetic panel’s responses to questions asked by researchers compared to answers to the same questions given by its human counterpart at the time of model training – is as important and possibly an even more powerful driver of the panel’s future prediction accuracy than its natural decay over time. Which of the two drivers affects the economics of the synthetic panel asset over time likely depends on many factors such as the specific research topic, the quality of the modeling, the quality of human training data, etc.
Different research topics will likely behave very differently over time: the current state of pulmonary diagnosis is probably more stable over time than, for example, the population’s preferences in pop music. Therefore, getting the initial accuracy of the pulmonary synthetic panel right is probably the more important factor driving its ROI. Alternatively, taste in music is much more fluid and unpredictable, so even the most accurate initial synthetic panel may not help make good predictions just a few months later. Whatever the relative importance of temporal decay and training accuracy may be, we propose that both of those forces are at play and that they are orthogonal to each other as independent variables. They shape the investment thesis for any synthetic panel independently and simultaneously.
Accuracy and decay framework
To make our framework applicable, we need to establish a generally acceptable benchmark to which we can relate the performance of synthetic panels over time. Fortunately, in consumer research, we have a readily available benchmark in human data. There are established best practices on how to measure accuracy, error, biases, etc., for example, as used by Park et al. While discussion of measurement approaches and best practices is an important area of research, it is not our focus here.
Keeping the concept of temporal decay and training accuracy simple, we first illustrate it visually with simulated data and then propose its possible generalized functional form. In our illustrations, each data point represents an answer provided by either a synthetic respondent (collectively a synthetic panel) or by a human (collectively a human panel). A data point may represent any possible survey answer, from a simple Likert-scale answer or a natural text response reduced to a two-dimensional vector. Note that in all illustrations, the human benchmark data is presented in orange and synthetic data is in purple.
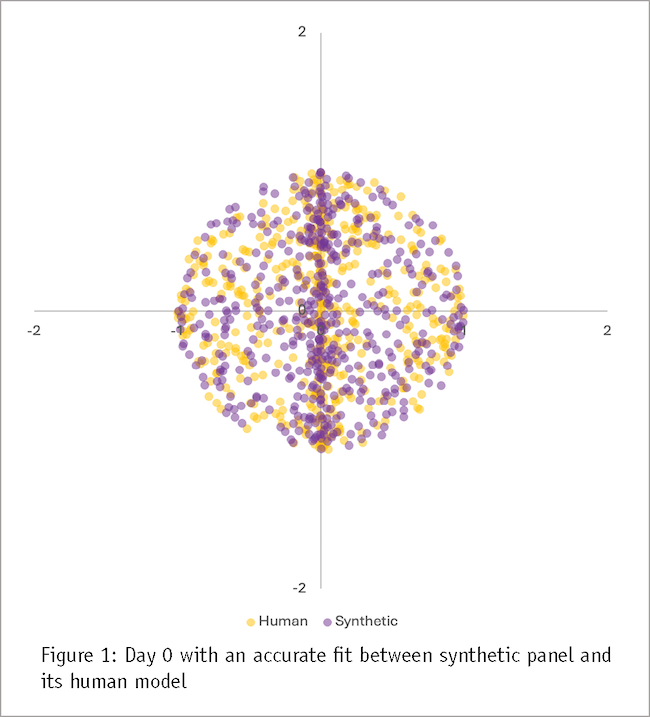
As a starting point (Day 0), imagine that we could construct a synthetic panel model that would answer all research questions as accurately as a human panel. Further, from the aggregate data perspective, the outputs of the two models would look indistinguishable in their means and variances. Figure 1 shows what such an accurate match could look like at the time immediately after the synthetic panel is constructed to match a human panel at that point in time.
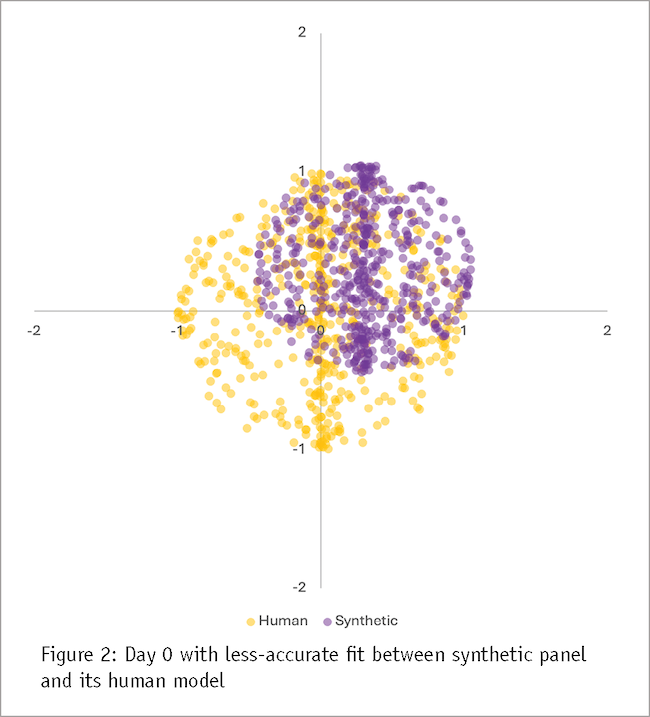
It is, of course, hardly realistic to expect that we could construct a synthetic panel with a 100% match between it and its human starting point. Therefore, a more realistic starting point would look like something we illustrate in Figure 2. Here, we see a small systematic bias (moving the synthetic answers toward the top-right quadrant) and different variance resulting from error which any model will be subject to, including gen AI. Note that the variance in synthetic data is smaller than human data variance. In practice, the variance may be greater or smaller but in our experience, synthetic respondents tend to provide answers more centered at the mean with less variance. It is possible that future models will do a better job of simulating variance closer to what a human panel would provide without excessive hallucination. However, today it is more likely that a synthetic panel will yield more uniform data than that coming from human answers. As an illustration of how data variance may differ between synthetic respondents and humans, see results of our earlier experiment2 in which we compared synthetic panel responses to human survey data.
Figure 2 still shows that the fit between the two models is good – synthetic responses are contained within the bounds of human answers – but the synthetic panel is less accurate. Over time, as the world around consumers changes and humans process and adjust to new information, they also change how they would answer the exact same questions that were asked before. Park et al. have shown that with about two weeks between the same two exercises, human answers show inconsistencies. They exhibit an “error.” A part of this error may be truly random – due to humans being inattentive or making mistakes – but part of it may be due to humans updating their decision criteria. Therefore, what may appear as a random human error to an observer who studies data to two identical surveys over time may reflect the fact that the world around us has changed and therefore answers to the same questions must also be different to be accurate. Without retraining, a static synthetic panel will eventually lose its match to reality.
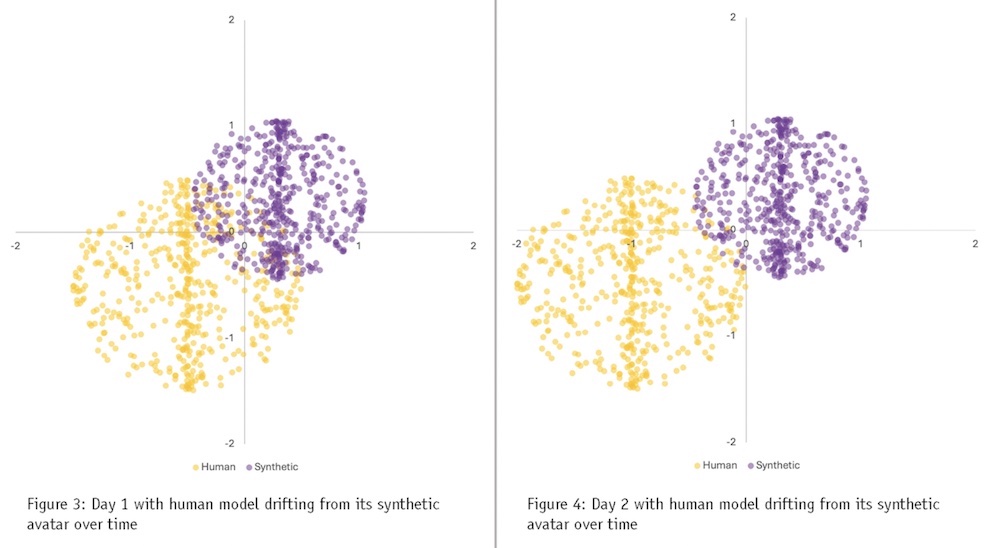
Figures 3 and 4 illustrate such drift. As humans update their preferences, their answers (again: human data is in orange) move toward the lower quadrant while the data from a synthetic panel (in purple) remains static, frozen in time in which it was constructed.
Ultimately, after more time elapses, the human and synthetic models no longer overlap, and one can conclude that answers provided by the two models over time may diverge enough to produce incongruent results: the synthetic panel has decayed beyond its useful shelf life.
To move from conceptual to practical (i.e., measurable) understanding and of data accuracy decay, we must describe this effect as a mathematic expression that can be estimated empirically. The fit accuracy between the synthetic panel and human data to a specific question over time could be expressed as a function of training accuracy and decay as follows: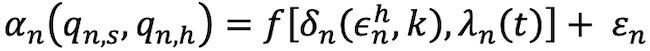
Where 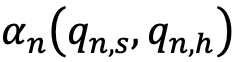 is a measure of answer accuracy match between the answers to a question n provided by the synthetic panel
is a measure of answer accuracy match between the answers to a question n provided by the synthetic panel 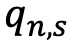 and the human representative sample
and the human representative sample 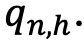 . It is a function of training accuracy
. It is a function of training accuracy 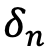 for a specific question and its accuracy decays in time
for a specific question and its accuracy decays in time 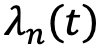 and
and 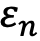 is a random error. Training accuracy is itself a function of training answers provided by humans
is a random error. Training accuracy is itself a function of training answers provided by humans 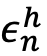 and function k, which is a parameter representing the model used to train the synthetic respondent panel using human answers as input. Accuracy decay
and function k, which is a parameter representing the model used to train the synthetic respondent panel using human answers as input. Accuracy decay 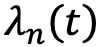 is a function of time elapsed since the time the synthetic panel was trained by the model k. It is specific to a question n because it is reasonable to expect that answers regarding some topics evolve quicker (e.g., taste in music) than answers to other topics (e.g., pulmonary diagnoses, ethical questions).
is a function of time elapsed since the time the synthetic panel was trained by the model k. It is specific to a question n because it is reasonable to expect that answers regarding some topics evolve quicker (e.g., taste in music) than answers to other topics (e.g., pulmonary diagnoses, ethical questions).
It is not the purpose of our article to hypothesize about the functional form of the accuracy function, but we can hypothesize that 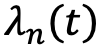 is decreasing in time and therefore overall accuracy
is decreasing in time and therefore overall accuracy 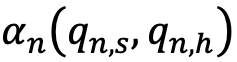 will also decrease in time. Regardless of how accurate the initial training is, the overall accuracy of a synthetic panel may decrease rapidly for those topics that are subject to rapid and significant mind-set updates within the human panel.
will also decrease in time. Regardless of how accurate the initial training is, the overall accuracy of a synthetic panel may decrease rapidly for those topics that are subject to rapid and significant mind-set updates within the human panel.
With this framework established, the next logical – and very practical – question a researcher would ask is “How quickly does the accuracy of a synthetic panel decay? Is it days? Months? Years?” Further research is needed to find out. Namely, empirical research could develop a more accurate functional form of temporal decay function and estimate topic-specific parameters and provide useful rules of thumb.
The economics of synthetic panels
Without a reasonably accurate estimate of temporal decay function, it is difficult to calculate the useful shelf life of any specific synthetic panel. There are, however, some reasonable data points and assumptions researchers may already have at their disposal to start understanding the economics of synthetic panels at least in the order of magnitude.
As an illustrative example, let’s assume that we are trying to understand the economics of a general-population synthetic panel focused on dental hygiene and, specifically, consumer preferences for power toothbrushes. (We are using this example because we have access to real data from a project we have recently completed.)
Following roughly the methodology that Park et al. used to construct a strong synthetic panel, its main cost stems from interviewing a large sample of humans who fit the desired use case. Such interviews help train the synthetic model in the subject matter in our example, on the topic of toothbrushes, flossing, oral hygiene, mobile apps, power toothbrushes, etc., and give avatars their “personalities.”
Construction of a panel with an incidence rate of about 15% and with N=1,000 for about an hour-long AI-assisted in-depth interview would likely cost around $25,000 to $35,000 in recruiting fees and honoraria only. (Based on typical costs of human panel recruitment.) Adding any license access fees to synthetic panel platforms ($5,000) and accounting for the cost of a data scientist to oversee the project and ensure data quality (25 hours at $200 per hour) would likely get us to about $35,000 to $45,000 in initial cost of the panel (not accounting for any future maintenance or retraining).
As an alternative, if we didn’t construct a synthetic panel for our research, we would likely choose to obtain answers to our questions in one or more online surveys. Depending on the nature of such surveys, we may not need as large a sample as was required in our training exercise. Going back to our practical example, we recently conducted a robust study with a sample of 500 qualified respondents (incidence rate of 15% and length of interview of 18 minutes) at a cost of about $5,000.
Frequency of surveys
A critical factor that will likely determine the return on investment in a synthetic panel is the frequency of its usage. In our example, to make the $50,000 investment in a “dental hygiene and power toothbrush users” synthetic panel economically attractive, it would have to replace about 10 surveys of 500 respondents at $5,000 cost per survey, holding everything else equal.
Practically speaking, however, the frequency of usage equivalence is probably lower than our estimate of 10 in our example. Here are some of the reasons why.
First, speed and availability: Having access to a synthetic panel allows decision makers to ask questions without having to commission formal survey projects. Availability of synthetic panel could lead to more ad hoc inquiries supporting more agile decision-making. The value of making faster, more-informed decisions is difficult to quantify but those factors are surely important positives in favor of synthetic panel economics.
Second, the cost of research project overhead: The price of a sample is only one part of the cost of market research. If synthetic panels allowed decision makers to avoid all or some of the cost related to designing and interpreting survey research, it would take significantly fewer projects before synthetic panels start looking economically attractive. If a traditional consumer survey cost an additional $10,000 in professional fees to a market research firm on top of $5,000 in respondent costs for the total cost of $15,000 for an ad hoc survey, the synthetic panel frequency of use equivalency would plummet to three-to-four surveys to recoup the initial $50,000 synthetic panel investment.
Clearly, the more human-answered surveys can be replaced by a synthetic panel, the better are the economics of its initial investment. However, we argue that companies do not have an unlimited amount of time to recoup this investment. Unless the synthetic panel is periodically retrained and updated, the answers it provides will eventually become inaccurate. This brings us back to the original topic of our inquiry – the useful shelf life of a synthetic panel. For the economics of a synthetic panel to work, researchers must not only get a certain number of uses from it to overcome its initial cost, but they must get that usage before the information value of the panel expires or drops to the level at which it is no longer believable enough to support business decisions.
Let’s return to our dental hygiene and power toothbrush example. If a power toothbrush brand typically launches a new product every two years and if that is the only time it commissions customer surveys, it would take three-to-four new product launches over a period of six to eight years to recoup its initial investment of $50,000. This would likely be a borderline acceptable capital investment for the company and it would be likely even less attractive if we account for possible major shifts in the market – such as technology innovations, new competitors or scientific and medical news – that could render the initial synthetic panel obsolete in a few years. On the other hand, if the brand conducts quarterly customer surveys, continually researches its markets and conducts several surveys or focus groups each quarter, it will likely make good sense not only to invest in a synthetic panel but to update it periodically to ensure it is always fresh and it incorporates any new shifts in its market.
Assess the point of decay
Practically speaking, it is difficult for a market researcher to recognize when the point of excessive decay of a synthetic panel has occurred, because a synthetic panel, even if it is stuck in time or was not accurate to start with, will always give a reasonable-sounding answer when prompted. An essential part of a synthetic panel’s value proposition for its user is trust in its accuracy, not only at the time of its commissioning, but as it ages.
An investment in a specific synthetic panel may or may not offer a long runway to researchers before its accuracy decays. That uncertainty is likely to undermine the trust researchers place in their synthetic panel. It is therefore critical for brands and market researchers to understand the decay curve for their panels and know at which point in time it should stop informing critical business decisions.
To address this uncertainty, industry and academia alike should invest in understanding the decay of synthetic panels and, more specifically, they should invest in empirical research to establish practical accuracy decay benchmarks for the use of market research practitioners.
References
1 Joon Sung Park, Carolyn Q. Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang and Michael S. Bernstein. “Generative agent simulations of 1,000 people.” Working paper. https://arxiv.org/pdf/2411.10109
2 “Seeing the future: GenAI synthetic respondents make their case to belong in consumer research.” Group Solver. https://app-na1.hubspotdocuments.com/documents/1914324/view/1046884476?accessId=fa02e1