
The good and the bad
Marco Vriens is CEO of Kwantum. He can be reached at marco.vriens@teamkwantum.com. Andrew Elder is chief research officer at Illuminas. He can be reached at andrew.elder@us.illuminas.com. Scott Holland is director marketing sciences at Illuminas. He can be reached at scott.holland@us.illuminas.com.
Every marketing researcher knows that survey data quality has become a major issue, even more so when surveying hard-to-reach audiences. There are many factors that determine data quality: survey design, question format, survey length, sample sourcing and modality. In this article, we assume that the researcher has made every attempt to a design a quality multimode survey, keep the length reasonable and select quality sample partners.
Despite all these efforts we can seldom (if ever) assume that the data we get back is completely valid or has all-around good quality. Any study can be susceptible to fake data, professional respondents or inattentive respondents who warrant being flagged as suspicious or of questionable quality. Though “inattentive” sounds benign in comparison to other, more actively problematic respondents, inattentiveness can be a serious issue for data quality. The extent to which we have respondents that were inattentive has been found to be in the 5%-50% range, as Maniaci and Rogge (2014) state: “Meaningful findings among attentive respondents were not present among inattentive respondents.”
It is this positive perspective towards the data quality issue – finding the respondents who did do their best to conscientiously read the questions and provide thoughtful answers – that often gets overlooked during the quality-review process. We argue that by identifying these respondents we not only gain meaningful insights from the data but also gain insight into quality.
Three stages of data quality review
Illuminas has developed a data quality process ranging from eliminating fake data to identifying the most valuable respondents. We use three stages (Figure 1) of review: behavioral flagging, content review and insight creation. The first two lead to either full elimination of respondents or respondents being flagged as having some quality issues. The third identifies our most valuable respondents. 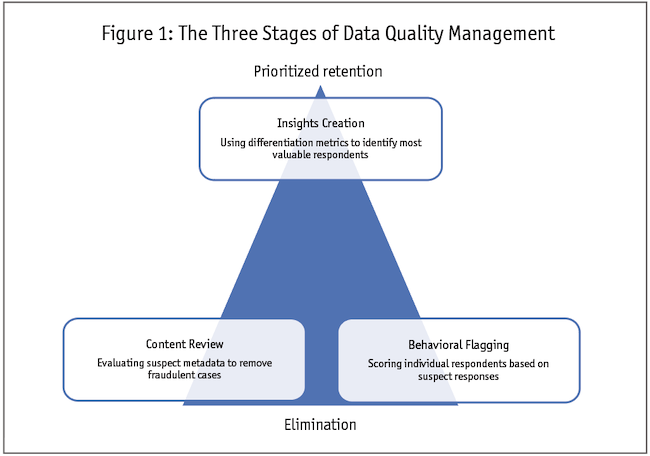
Behavioral flagging. The first step toward extracting high-quality insights requires establishing a better understanding of our low-quality respondents based on their survey responses. Sometimes these are referred to as inattentive or careless respondents. The decision of whether to exclude partially depends on judgment. Elimination can be based on having too many red flags or just one unacceptable red flag.
For some respondents, the implications of a single metric may just look too bad. When a respondent completes the survey in an unrealistically short amount of time, we can safely assume they did not read the questions sufficiently carefully and/or did not allot sufficient time to think about a response and instead just mechanically completed the survey. For example, if a survey realistically takes 15 minutes to complete and we get a survey back that was completed in under five minutes we may deem this respondent fraudulent (e.g., Pozzar et al., 2020). To detect inattentive or careless respondents, we look at a range of red-flag metrics such as:
- Were they speeding (if yes, how extreme)? Typically, a range is specified below which we believe there was some speeding going on.
- Did they have an excessive amount of don’t-know or opt-out responses or, alternatively, too many or too few selections in multi-punch questions? (Excessive or minimal selections in check-all-that-apply questions is in and of itself not a reason to exclude someone but in the presence of other quality-concern flags it may be the tiebreaker.)
- Did they give odd responses to open-ended questions? For example, “I like it,” “very good and well” and other variations of affirmative phrases.
- Did they fail a knowledge verification question? For example, “Describe the topic of the survey.”
- Do qualifications look overstated? For example, someone may say they are the CEO of a $1 billion company; not impossible but extremely unlikely.
- Were they straightlining or did their responses to battery questions lack meaning?
- Did they give inconsistent responses to questions probing the same topic?
- Did they answer obvious questions in an unobvious way? (e.g., Have you visited all the countries in the world?)
Based on our investigation we can give a point for each red flag and may decide that respondents with three red flags or more are removed from the survey. The exact elimination criteria are determined study by study and there will always be some art and science necessary to conform to different topics and question formats. We recommend making the decision process transparent and as consistent as possible across studies (especially tracking studies).
Behavioral scoring will typically have a group of respondents who fall in a gray area: They are not bad enough to immediately be deleted but their responses don’t look high-quality either (some have referred to such respondents as slackers or tolerables). Ploskonka and Fairchild (2022) call out another type of gray-area respondent: the pros. According to these authors some respondents may do 50 or more surveys a day.
Of course, there are other reasons why we might get suspicious. For example, in cases where the survey is conducted by interviewers, the interviewers may take shortcuts or otherwise lead the interview against instructions. Further, aided and unaided awareness can sometimes reveal bias towards brands included in the aided question appearing in the unaided response. It is important that the researcher adapt their behavioral review to the realities of the survey mode.
After this step, some respondents will be removed and others will be retained but they will have a quality flag that we may use at some later stage.
Content review. One concern we hear a lot from our clients is: Are the respondents truly qualified to be included in our study? Even though they passed the screener questions there can be several reasons to disqualify a respondent from the sample if we can determine that they are unlikely to be who they claim in the survey:
- responses came from a survey farm (see Pasternak, 2019);
- responses came from colluders (the same IP address is found among responders);
- responses were generated by bots or some automated tool; or
- responses were generated from some standard script.
If we can determine that a completed survey originated from a survey farm, this immediately disqualifies the respondent – for example, if respondents have very similar IP addresses and their responses to the screener questions are nearly identical, etc. Duplicates can be identified if the sample is obtained through multiple panel sources. By comparing the IP addresses, we could identify if a respondent entered the study twice. Respondents with duplicate IP addresses are eliminated. If a bot or automated tool was used to generate survey responses, we can catch that by using what is referred to as a honey pot, which is a hidden form that a human user is unable to see but a bot would be able to see. If a honey pot has data in it, that means that a bot or other automated tool was used to read the code of the website and fill in the data.
Insights creation. Using a scoring algorithm means some respondents may have one or two red flags but are not eliminated from the sample. The content review may reveal borderline cases of similarity or generalized data that are more uninteresting than they are blatantly poor. These respondents are not quite bad enough to be removed but the search for quality can leave the researcher with more doubt than confidence.
To help resolve this uncertainty, we turn to the other side of the quality spectrum: respondents whose answers indicate that thought and care were used to provide high-quality answers. Just as we identify straightlining and poor discrimination as signs of quality issues, we can also identify those respondents who have more differentiated and informative responses than others.
How does this work in practice? For a branding study we can assume higher-quality responses will be more differentiated across brands and attributes; one brand will be a value leader, while another will own innovation.
The search for differentiation is supported by research: Neuert (2021) found that respondents differentiated less in later parts of a survey. This was indicated by lower differentiation metrics and by less fixation time as indicated by eye tracking. Different parts of a survey can lead to more- or less-differentiated responses. However, respondents can also differ in terms of how differentiating their responses are. One can use the differentiation metric used by Neuert (2021): Pd = 1 - Σ (Pi)2), originally introduced by Krosnick and Alwin (1988). This metric can be calculated at the individual level.
Back to our branding example, say we have 10 attributes and these are evaluated on a three-point importance scale (not important, somewhat important, critically important). Consider two respondents. One selects critically important 80% of the time (eight of 10 attributes are considered critically important). The somewhat important gets 20%; none of the attributes are unimportant. The Pd value for this respondent for this survey section is 1 – (0.80)2 – (0.2)2 = 0.32. A second respondent has 40% not important, 30% somewhat important and 30% critically important. This gives a Pd value of 0.66. A higher Pd value means more differentiation.
A case study example
A commercial project among IT professionals was conducted in the fall of 2022. This was part of a tracking study and the survey contained several batteries of brand attributes and attitudinal statements. One battery had the following format: First, we asked “How important are each of the following scenarios when considering a provider?” The scale: not important, important, critically important. Respondents could select from a set of 10 scenarios (all that apply). Next, for those scenarios a respondent deemed critically important, they were asked which providers (out of a list of 10 brands) they preferred for each given scenario. Among the choices were big brands such as Microsoft, IBM, etc., and mid-tier brands such as Salesforce and several smaller brands. See Table 1 for the overall results.
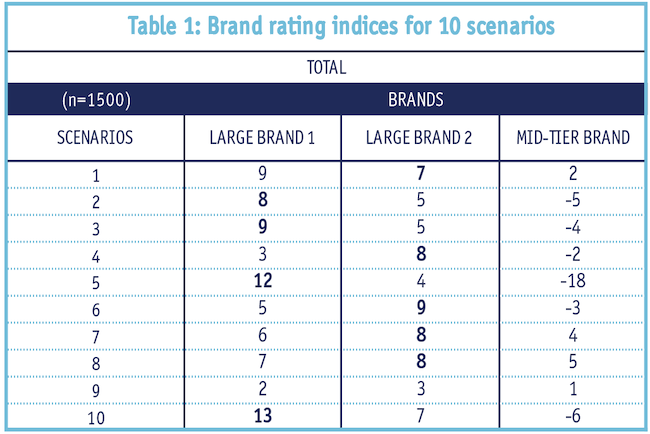
As we can see, the two bigger brands are always better than the mid-tier brand on every attribute. Can a brand really be among the best across all scenarios even in areas where other smaller brands had clearly specialized? The brand halo effect could be partially responsible for this result – that is, some respondents, instead of evaluating a brand attribute-by-attribute, may have a strong overall opinion of it that colors their response to each attribute evaluation.
Respondents can differ in how many scenarios they select as vitally important. Respondents can also differ with respect to how many of these vital scenarios they associate with a given brand. To identify those respondents who can give us enhanced insight, we use the following steps:
- Calculate individual-level differentiation metrics (Pd), for both importance and association questions.
- Use cluster analysis to separate low-differentiating respondents from differentiating respondents.
To illustrate this, we show a simplified example. After running a cluster analysis on the P metrics, we identified two segments: a low-differentiating segment (very similar to Table 1 result) and a high-differentiating segment.
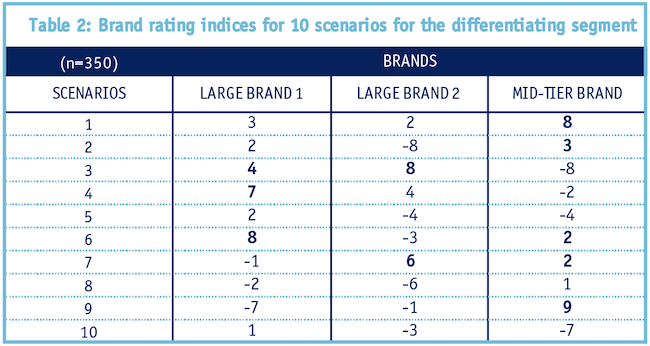
In Table 2 we show the results of the high-differentiating segment.
For this subgroup, we can see the results are more interesting. Brand 1 stands out on Scenario 4 and 5, Brand 2 stands out on Scenario 3 and 7, and the mid-tier brand stands out on Scenario 1 and 9. Though we cannot show the real data here, Scenario 1 was the area where the mid-tier brand had specialized.
From a quality perspective, both segments presented viable and realistic brand scenarios. While the differentiating segment was clearly more insightful (and directly relevant to our research goals), the low-differentiation segment became more understandable in contrast. This process allowed us to identify greater depth to brand perceptions in the market and also validate that a lack of differentiation actually reflected a sizeable and important portion of the market.
Response quality can vary
Marketing research professionals take a variety of precautionary measures to counter fraud, misrepresentation or inattentiveness. Quality review often focuses on eliminating fraudulent data or data from respondents whose responses are questionable based on quality metrics. But as we have shown, while data quality can vary across respondents, it can also vary within the data of one respondent. And just because a respondent falls in the low-quality category for one battery of questions, that doesn’t mean all their data should be disregarded. Particularly with B2B audiences, where complex qualifications and finite audiences mean that every respondent counts, taking the extra steps outlined above can help mine every ounce of gold from our industry’s most precious resource.
References
Kaminska, O., McCutcheon, A.L., Billiet, J. (2011). “Satisficing among reluctant respondents in a cross-national context.” Public Opinion Quarterly, 74, 956-984.
Krosnick, J.A., and Alwin, D.F. (1988). “A test of the form-resistant correlation hypothesis.” Public Opinion Quarterly, 52, 526-538.
Maniaci, M.R., and Rogge, R.D. (2014). “Caring about carelessness: Participant inattention and its effect on research.” Journal of Research in Personality, 48, 61-83.
Neuert, C.E. (2021). “The effect of question positioning on data quality in surveys.” Sociological Methods and Research, 1-17.
Pasternak, O. (2019). “Market research fraud: distributed survey farms exposed.” GreenBook blog.
Ploskonka, D. and Fairchild, K. (2022). “Is there an antidote to the cheater epidemic?” In: Sawtooth Software Proceedings, Orlando, Fla., 1-20.
Pozzar, R., Hammer, M.J., Underhill-Blazey, M., Wright, A.A., Tulskey, J.A., Hong, F., Gundersen, D.A., Berry, D.L. (2020). “Bots and other bad actors: Threats to data quality following research participant recruitment through social media.” Journal of Medical Internet Research. Preprint.
Zhang, C., and Conrad, F.G. (2014). “Speeding in web-surveys: The tendency to answer very fast and its association with straightlining.” Survey Research Methods, 8, 2, 127-135.