
When bad data looks good
By Vignesh Krishnan, Chief Technology Officer, Rep Data and Steven Snell, Head of Research, Rep Data
Do you ever think your data is too good to be true? Have you seen respondents that make you question the quality of every other response in your data set? Market research has long been plagued by fraudsters – respondents who deliberately misrepresent who they are or where they are in order to access your study and steal your incentives. Fraudsters traditionally reveal themselves as poor-quality because they finish too quickly, say “good” as a response to every open-ended question or give conflicting answers. 
Fraud has evolved considerably and the new class of fraudsters is more sophisticated and tech-savvy than ever. They are adept at giving thoughtful-looking answers and evading traditional techniques for identifying bad responses. In short, fraudsters are getting good at looking good.
The evolution of survey fraud
Industry veterans may describe fraudsters as hustlers with dozens of email addresses attached to dozens of survey profiles or as offshore click farms staffed by low-skill workers who are paid per survey attempt. In reality, the barrier to entry for fraud is lower than ever because emerging technologies, especially AI, make it easy for fraudsters to commit fraud at scale. The current industry landscape further enables significant amounts of duplication across panels.
Bad actors use advanced developer tools to manipulate device signals, run concurrent virtualized instances and accurately emulate other hardware environments. Our proprietary Research Defender fraud detection platform routinely detects survey respondents who manipulate their real-time communication (RTC) configuration, use emulators, subnets, web proxies and developer tools. The system is being targeted by coordinated bad actors, not genuine respondents.
Advances in AI add fuel to the fire. A recent academic study warned of a “potential existential threat,” showing that LLMs or agentic respondents can pass attention checks and give coherent, passable survey responses.1 Others have shown that browser-based agents can enter surveys in a leading research platform.2 Taken together, the evidence suggests AI will make fraud faster, easier to perpetrate and less easily detected.
Tech-enabled survey fraud is already pervasive
Our research demonstrates that tech-enabled fraud is already pervasive across the online survey ecosystem. In a comparative study of six online consumer sample providers (Figure 1), including panels and aggregators, we measured the prevalence of tech-enabled fraud by leveraging Research Defender’s digital fingerprinting. This identifies tech-enabled fraud through respondents’ use of suspicious technology and by comparing survey entrants against lists of known bad actors.
Holding constant the survey design and sampling criteria, we observed high rates of tech-enabled fraud across the six separate sample sources – ranging from 14-20% of respondents in each sample. More generally, Research Defender recommended blocking as fraud a total of 25-42% of respondents in each sample. Other flags contributing to these total fraud rates include markers for duplicate entrants, hyperactive respondents and low-quality open-ended responses, which may also point to tech-enabled fraud.
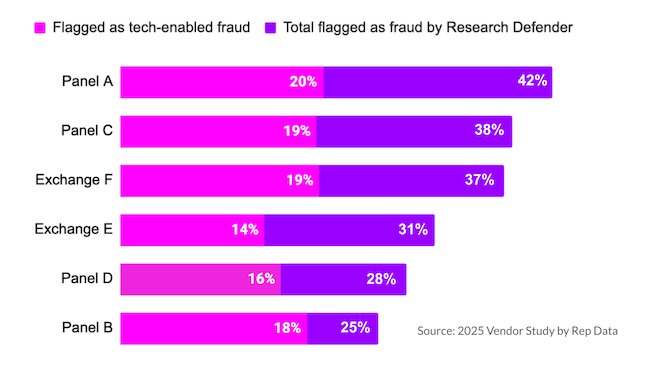
Fraudsters routinely evade data quality checks
Conventional wisdom proposes that survey fraudsters can be sniffed out through quality checks or close readings of open-ended responses. On the other hand, we routinely hear from researchers that their data still feels unreliable after several rounds of data cleaning, suggesting that traditional data quality checks are inadequate to root out fraudsters.
To test this proposition, we conducted additional research, using Research Defender to flag fraud but allow the fraudsters into our survey. While Research Defender terminates respondents flagged as fraud by default, in this instance we disabled this feature in order to determine whether fraudsters could be detected through standard techniques measuring attention and cleaning data.
In a separate study of more than 2,000 consumer respondents, 33% of respondents were flagged by Research Defender as suspicious and 67% were otherwise considered qualified entrants. Regardless of their fraud status, all of these respondents were allowed to participate in our survey. Their responses were then subjected to a rigorous machine learning-powered, human-supervised data cleaning process, in which 27% of all respondents were determined to be inattentive or of poor quality.
The mosaic plot in Figure 2 represents the intersection of Research Defender’s fraud detection and traditional data cleaning. Although the biggest group, it is important to note that just 50% of respondents were found to be qualified and attentive, passing fraud detection and data cleaning checks. Perhaps more alarming still, if we focus on the right column, we see that the 33% of respondents flagged as fraudsters are split between 10% who are also discovered in data cleaning and 23% that have no markers of inattention or low response quality. Stated another way, nearly 70% of the fraud discovered by Research Defender successfully blended in as quality data. If the fraud makes it in the front door it is likely to never be discovered.
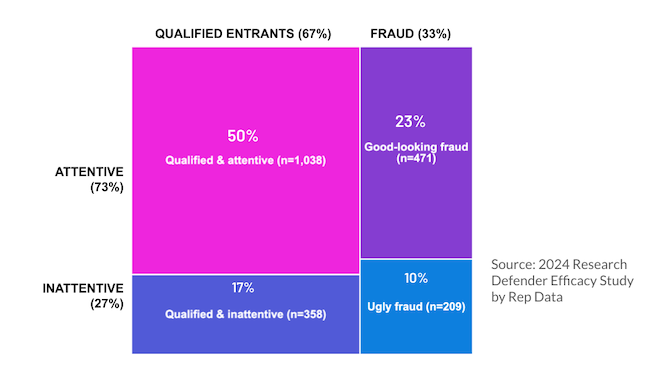
Blocking good-looking fraud in the age of AI
Bad data is bad, even if it looks good, and undetected fraud can add bias to research, even when the fraud gets through data cleaning. We’ve observed that fraudsters attenuate differences in brand ratings and bias estimates across health and policy outcomes, political polling and demographics.3 The challenge of collecting high-quality data hinges on our ability to detect and block good-looking fraud.
When it comes to detecting tech-enabled fraud, it’s less a question of what respondents say and more how they say it. That is, survey responses themselves are of limited value because fraudsters give passable answers. Instead, we turn to the paradata – data about how the survey responses are generated.
Especially when it comes to agentic respondents, we recommend tech-forward defenses to explicitly target LLM trackers, automated scripts like Selenium, Playwright and specific device signals – such as those from OpenAI – while simultaneously utilizing digital fingerprinting and virtual machine verification to expose identity spoofing.
Beyond technical detection, researchers should leverage tools to analyze behavioral elements like unnatural cursor movement, programmatic typing and copy/paste use. We also recommend measuring respondents’ activity across the ecosystem to understand how many surveys each respondent attempts per day. We have seen the number of hyperactive survey respondents increase dramatically over the past year.
Staying a step ahead of fraud
Research Defender is constantly evolving to stay ahead of tech-enabled fraudsters. Given our wide visibility into the survey ecosystem, having scanned and scored more than 5 billion survey attempts in the past 12 months, we can observe and build protections against new forms of fraud – AI or otherwise – before other organizations even perceive them as threats. To learn more about our innovations in blocking tech-enabled fraud, visit repdata.com.
References
1 Westwood, S. J. (2025). “The potential existential threat of large language models to online survey research.” Proceedings of the National Academy of Sciences, 122(47), e2518075122.
2 See, for example, https://bsky.app/profile/mdigiuseppe.bsky.social/post/3lzg53u334s2h.
3 Learn more about our research on research at https://repdata.com/research-on-research/.