Editor's note: Joe Murphy is director of the program on digital technology and society in the survey research division of RTI International, a Research Triangle Park, N.C., research company. Murphy is based in Chicago and can be reached at jmurphy@rti.org. This article appeared in the January 13, 2014, edition of Quirk's e-newsletter.
Over the last couple decades, survey response rates have been in decline. This may be partly due to the public being inundated with survey requests and many lack the time - or interest - to participate in lengthy surveys. At the same time, a new source of data has emerged where consumers are voluntarily sharing the ins and outs of their everyday lives: social media.
On the surface, you wouldn't think social media could replace a survey. And you'd be right! Good surveys are carefully-designed and -tested instruments that accurately measure opinions and behaviors from a representative sample of participants. Social media is more of a free-for-all - not everyone posts and those who do may post frequently or infrequently and on any topic under the sun. But given the increasing difficulty of getting people to complete surveys, plus the incredible popularity of social media, are there ways to draw on the latter to inform the former?
Predict some characteristics
RTI International conducted a study to see whether we could use social media to at least predict some characteristics of respondents in our survey. The idea here is that surveys need to be short if people will participate, therefore you cannot ask all the questions you would like. Supplementing surveys with other sources of data can help fill in the blanks for missing questions or when respondents answer some but not all of the questions.
Our design was simple: We asked approximately 2,000 respondents participating in a representative Web survey whether they use Twitter. About 20 percent said they did. Next, we asked if they would provide their Twitter handle (i.e., username) and allow us to merge in their public tweets with their survey responses for internal analysis. About 25 percent of those who used Twitter said we could. With our resulting sample of approximately 100 respondents, we set about seeing whether tweets could give us the same information we collected in the survey.
The survey dealt with health, voting, demographics and other opinions and behaviors. We were interested to see whether a person's recent tweets could predict characteristics like gender, age and income, and more substantive items like who the respondent voted for in the last election, health status and symptoms of depression. We randomly divided the sample in two groups and masked the survey responses for one group.
Next, we set about gathering the tweets for both the masked and unmasked group. We used the freely-available twitteR package for R to make a call to the Twitter API and collect each respondent's 1,000 most-recent tweets (or fewer if they didn't tweet this much). We made no restrictions on the types of tweets we included and, as expected, the topics ran the gamut from current events to discussions of recent purchases to food and even Gigglemonsters (a brand of kids' accessories, we came to learn). We used two methods to predict the responses in the masked group: automated prediction using a computer algorithm and human review.
Computer prediction
For the computer prediction, we fed the tweets and survey responses (for the unmasked group) into a computer algorithm based on the k-nearest neighbor method that makes predictions based on multiple data points and cases that resemble other cases. This is a relatively simple, fast and scalable method that can handle a large number of predictor variables so it was well-suited for a task like this.
The downside was that we had relatively few cases with which to work. Data mining like this usually draws on big data in the millions, not little data in the hundreds. Nevertheless, the data were sufficiently large to make predictions for the masked group of respondents.
Human review
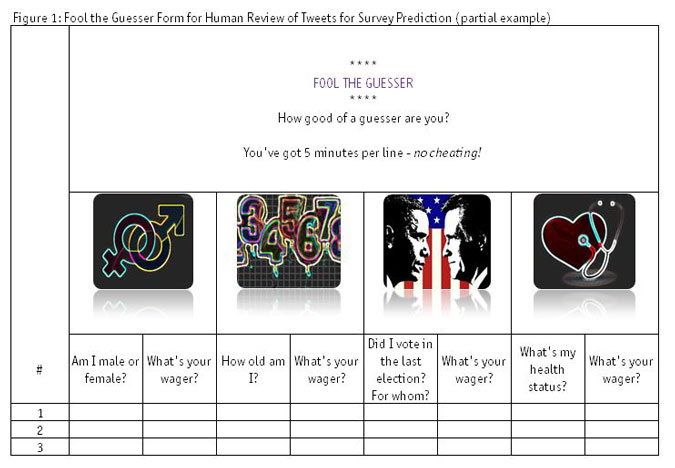
For the human review, we took quite a different approach. Inspired by the age- and weight-estimating carnival game Fool the Guesser, we set it up like a game. Three reviewers from our professional survey staff were given the 1,000 most-recent tweets for each respondent and given five minutes per respondent to skim through and make a prediction of six characteristics of interest using pre-specified ranges for each characteristic. They were also asked to provide a wager on a scale from 1 to 5 indicating their confidence in each prediction. Figure 1 depicts the coding form the guessers were given to fill in their predictions.
Tallied the accuracy
We then tallied the accuracy of the computer and human predictions overall and compared to what we would get from a coin toss or roll of a die to see how much better than random each method performed. We could determine accuracy by unmasking the survey responses and comparing the prediction to the actual survey response given.
Figure 2 shows that, overall, the computer and the humans were mostly better than random in predicting these characteristics. While there was some variation among the human reviewers, on average they did quite well guessing gender and age. These characteristics seemed rather evident to the reviewers in reading through the content of the tweets. However, the computer did a better job of predicting more hidden characteristics (e.g., health and depression), which were infrequently discussed outright in tweets but were detectable in patterns from other variables in the model. When we looked at different levels of wagers given by our human reviewers, we saw better accuracy with higher wagers (as expected).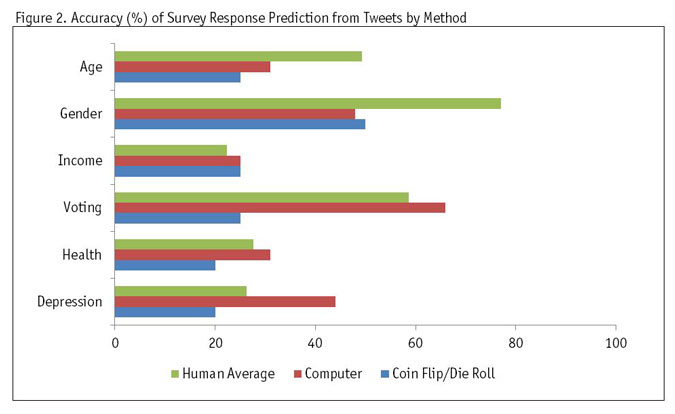
Does it mean anything?
So yes, this was a fun experiment. But does it mean anything for surveys and the prospect of harnessing information from social media in research? We found that even with a small set of respondents, tweets can add some information about respondents to help predict missing characteristics or outcomes. Because Twitter data are primarily public and easy to manage - 140 characters or fewer! - they are a useful resource for this type of quick analysis.
For basic demographics (perhaps stereotypes?) human prediction worked better than the computer algorithm. This may be partially due to the fact that we began with so few cases for analysis, compared to what the computer is accustomed to. The computer did do well, however, with more hidden characteristics - the types of things our surveys are really out to measure in the end - so it is promising that we may have this as another tool for data analysis.
Several grains of salt
While these results were promising, we cannot stop here and simply recommend that you start collecting tweets in your survey and call it a day. These results should be taken with several grains of salt.
First, most of the respondents in our sample were not on Twitter. While Twitter is gaining in popularity, it does not cover everyone and those who use it are more likely to be younger, better educated and more well-off than those who don't. Second, most who did say they used Twitter did not give us permission to access their tweets. We felt it was right to seek this permission and let the respondents know exactly what we planned to do with the data before collecting it. As a result, more said no to letting us access their tweets than yes. Finally, we haven't yet compared this method to more standard approaches in survey research for filling in missing pieces of information, like statistical imputation. We do plan to make this comparison and want to make sure more traditional methods aren't cast aside with the enthusiasm for the vast, fast and cheap prospects of social media.
Continue exploring
But given that 1) Twitter data are primarily public, 2) access to recent tweets is free through the Twitter API and 3) more and more are sharing online (and not in surveys), we need to continue exploring creative, practical applications like this to realize social media's potential in research. Social media has potential to supplement surveys in other ways as well. For example, one can monitor social media as source of conversation from which to draw context when designing a questionnaire, stay in touch with panel members via social media platforms, integrate personalized content from social media sites with a survey (with respondent permission, of course) or even use social media for the dissemination of public study results.
We hope that others will learn from the approach and will be inspired to develop and share their own!
This article is based on work funded by RTI International. The author would like to acknowledge the contributions of Justin Landwehr and Ashley Richards, also of RTI International.