Editor’s note: Frank Kelly is SVP global marketing at Lightspeed Research, Boston. Phil Doriot is founder and principal at ONE Analytics and Consulting, Atlanta.
The oil embargo of 1974 was a major wake-up call. Suddenly, large, inefficient cars were out of favor as gas prices skyrocketed and supply was limited – and for a time rationed. Demand for small cars surged while Cadillacs went unsold. The American automobile industry rapidly lost share to the Japanese. It was hard to understand how the U.S. automobile industry could be good at producing only big cars when the need was for small cars.
It’s similarly perplexing why the marketing research industry continues to produce long surveys when consumers clearly prefer shorter ones. It seems the industry would rather invent new ways to conduct research than to fix the principal way that it is done today. The problem is simple:
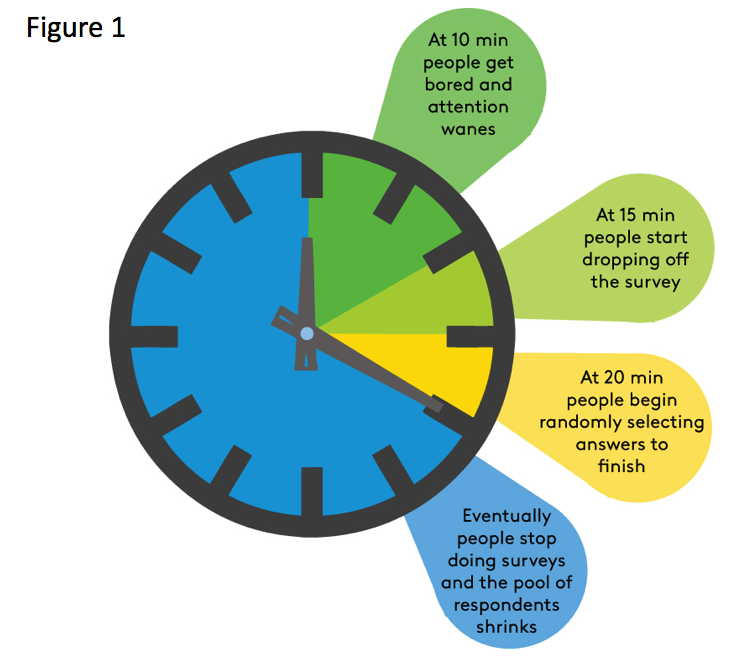
On average, online surveys take 20 minutes to complete (Figure 1). After about 10 minutes people start to get bored and attentiveness wanes. By 15 minutes respondents start dropping off the survey rather than completing it. At around 20 minutes, those remaining begin randomly selecting answers to get through to the end. After starting and dropping out of a couple of long surveys people stop doing surveys and the pool of available survey respondents shrinks.

While the need for shorter surveys has been evident for a decade or more, it took the proliferation of smartphones and people’s uncanny preference to organize their lives around these devices to wake up the industry to the need for shorter and simpler surveys.
Here are some of the solutions that have been explored:
- abandon the attitudinal data model in favor of behavioral data methods;
- shorten surveys by eliminating redundancies and writing succinct questions;
- gamify surveys so that they are entertaining;
- change the style of survey questions; and
- modularize surveys.
Most of us in the industry feel that the first solution will be a matter of degree to which some attitudinal questions will be replaced by observed data; we are seeing clear evidence of this already. Shortening surveys is something we should and must do just to make them possible on small-screen devices, but the pace of that change is too slow and it is unlikely that will be the answer. Survey gamification is also an important part of the solution. We need to continually challenge ourselves as researchers to find better and more engaging ways to ask questions but gamification does more to help people stay engaged than to shorten surveys, so it is again a partial solution.
Survey modularization is simply breaking up surveys into parts which can be completed either by different people or by the same person over time. If you opt for the same person over time, you still have some respondents, if not most, who do not complete all parts and therefore the issue is the same: What do you do about the missing data?
For completeness, there are three options:
- Survey sections or modules completed by different people and matched together.
- Actual answers plus predicted answers to complete the data set.
- Some questions answered by everyone, some by partial sample and proceed with incomplete data.
The first option – matching different respondents together to complete a survey that each respondent only completed a part is a data fusion technique – is only as good as the linkage variables. This method relies on predictors that require those respondents who answered the first module to also answer the second module the same way using one or several variables such as age and sex to match together data from different people.
We believe that the third option is a solution that could be used extensively but researchers are so accustomed to having a data set where everyone completed every question that it is hard to gain acceptance for it. The truth is that many questions in a long survey are not that important and previous research has identified techniques to distinguish which questions need a large sample and which ones do not. Briefly, there are two key factors: if a question has a large number of answer choices, you probably need a large sample and if a question is central to the research objective, you probably want the whole sample to answer it. We need to move from range questions to more binary ones which are easier and faster to answer. We have analyzed a wide cross section of surveys and in some cases less than 10 percent of the questions need to be answered by the full sample and typically less than half.
We are encouraged by the progress that has been made with the second option. A few years ago, several papers were written on this topic and the conclusion at the time was that available techniques were only giving us about a 75 percent to 80 percent chance that the manufactured answers were correct; that was deemed insufficient. Advancements in data-mining approaches now have pushed the predictive data to over 90 percent, which is an acceptable level of accuracy for most research purposes.
Shorten and improve
So how do we shorten surveys to improve response rates, decrease respondent fatigue and improve data quality? How do we make surveys short and engaging enough to reach segments that are accessible only through their mobile technology? We’ve mentioned several alternatives as potential solutions, each of which one could characterize, to some extent, as old school. These methods require a great deal of knowledge and a prior application of research design principles to make them work, to the extent that they work at all. Experience suggests that these solutions often fall short due to the framework in which they are embedded. These old-school approaches attempt to consciously design in the solution.
Data-mining and machine-learning algorithms (DM/ML) turn the problem on its head. Simply put, these algorithms allow a robust solution to emerge by borrowing information from like respondents. By like respondents, we mean like in traditional ways – demographics – but additionally andn its head. Simply put, the old idea. like also refers to ways that become apparent only after data-mining and machine-learning have scoured the data for important yet non-apparent patterns – patterns you might otherwise think of as segments.
Instead of complicated parsing of surveys and strict quota management of respondents, utilized only to ensure a design matrix is filled out, the DM/ML technique simplifies the problem. Long surveys are partitioned so that any single respondent need answer as little as 25 percent of the questions from the full survey. We either let the data collection technology randomly present a unique question subset or we create a few partially-overlapping subset versions of the survey. Once data collection is finished, we put the incomplete data set into the DM/ML algorithms, seed it with the patterns we are aware of, ask it to find other meaningful patterns and then make forecasts about each individual respondent’s missing responses, using information from other respondents who are like them in the identified patterns.
We will close by showing an example of the sort of results that are achievable using the DM/ML technique (Figure 2).
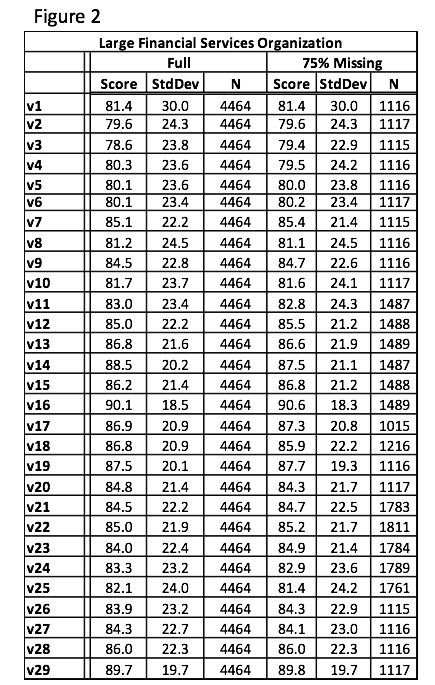
Results from the full data set are in the left-three columns (N=4,464); results from the partial data set (25 percent of the questions presented to a respondent) are in the right-hand columns. Comparing percentages derived from the complete vs. incomplete data sets, the biggest difference is 1 percent. Standard deviations are essentially the same. The only noticeable difference is in the N for the right-hand set of results – reflecting the partial data set for each question.
What does this mean for marketing research? We think it means the following:
- elimination of long surveys;
- lower data collection costs;
- less respondent fatigue;
- better data quality; and
- meeting your respondents where they live – on mobile devices.
There are other implications as well, particularly if you can make the jump to deploying binary question-based surveys. For mobile applications researchers can adopt the use of binary response scales. This change makes questions much shorter and more direct and eliminates the need for horizontal scrolling and other clunky mobile adaptations that make taking a survey on a mobile such a miserable experience. When done right, binary response scales can further improve data quality and increase the accuracy in response prediction. It also addresses several other traditional problems with survey data but that is the subject for another article.