
It’s the right thing to do
Editor's note:Tracy Tuten is vice president of qualitative research at Illuminas: A Radius Company. She can be reached at tracy.tuten@us.illuminas.com.
The promise of synthetic data in market research is dazzling: faster results, lower costs, privacy safeguards and the ability to simulate hard-to-reach audiences. With the rise of generative AI and machine learning, synthetic datasets – designed to mimic real human behavior – are now fueling everything from predictive modeling to segmentation strategy. But behind the sheen of innovation lies a growing ethical blind spot: Are we adequately informing participants how their data will be used to train synthetic models, power simulations and even construct data-driven “digital twins”?
As a qualitative methodologist and research strategist, I find myself both intrigued and unsettled by this question. Synthetic data is often positioned as a privacy-protecting solution but its creation depends, paradoxically, on real-world data collected from actual participants. If their contributions are being used not only to support a single study but to teach machines how to mimic human thought and behavior, then the principle of informed consent which is so foundational to our industry must evolve accordingly.
This article argues that the research community must expand its definition and implementation of informed consent to align with the realities of synthetic data and digital-twin applications. We must go beyond vague clauses in privacy notices and create meaningful, participant-centered transparency that earns and deserves public trust.
Synthetic data isn’t as detached as we pretend
Synthetic data is frequently described as anonymized, privacy-safe and non-identifiable. On the surface, this is true. Once the data has been modeled and generated, it no longer contains direct personal identifiers. But this framing can be misleading.
Behind every synthetic dataset lies a foundation of real human data – answers, emotions, patterns and preferences that were initially provided with an expectation of bounded use. When we use that data to train AI models capable of generating human-like responses, we’re doing more than anonymizing information. We are encoding participant behavior into models that may simulate, extend or replicate that behavior in new contexts for years to come.
This is particularly true when the goal is to develop digital twins – synthetic constructs that mirror the behaviors or decision-making of an individual or narrowly defined persona. While most synthetic datasets aim to represent general population patterns, digital twins are designed to simulate the choices of “someone like you” – or even you, in some cases – based on a full data exhaust of prior behavior. Yet many participants have no idea this is happening.
The ethical imperative: informed consent, reimagined
Informed consent has long been a pillar of ethical research practice. Participants must know what they’re agreeing to, how their data will be used and what risks they might face. But current consent practices often fall short when it comes to AI training and synthetic data applications.
Most traditional consent agreements are:
- One-time events rather than ongoing processes.
- General in nature, failing to describe specific AI-related use cases.
- Silent on future uses, such as model updates or deployment in new contexts.
- Grounded in a pre-AI understanding of what “data use” actually means.
This outdated consent structure creates a mismatch between participant expectations and industry practices, undermining transparency and potentially trust. To restore that trust – and ensure ethical rigor – consent must be expanded in scope and reimagined as a dynamic, ongoing process.
Here are the key areas where consent must evolve:
Nature of simulation
Participants may believe their data is being used for statistical analysis, not to simulate how someone like them might think, feel or act. They deserve to know that AI models trained on their responses might generate synthetic responses that resemble their own.
Creation of digital twins
In some applications, organizations use real data to generate one-to-one “clones” of an individual’s behavior profile. This is no longer generic modeling – it’s individualized simulation. Consent for this kind of use must be explicit and separate from general research consent.
Bias amplification
AI models trained on real-world data can inadvertently reproduce or even amplify underlying biases. Participants should be informed that their data might contribute to models that reflect societal inequalities or demographic skew, even if not intentional.
Loss of nuance
Synthetic data often performs well on factual queries but lacks the emotional depth, social context or personal nuance of real human responses. Participants should understand that their voices may be distilled into something less rich or representative than intended.
Future uses of synthetic models
Unlike survey data, synthetic models may live on and be repurposed for new research, simulations or strategic planning. Consent should clarify that participation may have longer-term implications, especially in dynamic systems that update over time.
A checklist for expanded informed consent
To responsibly integrate synthetic data into market research, researchers should revise consent processes to address the following components.
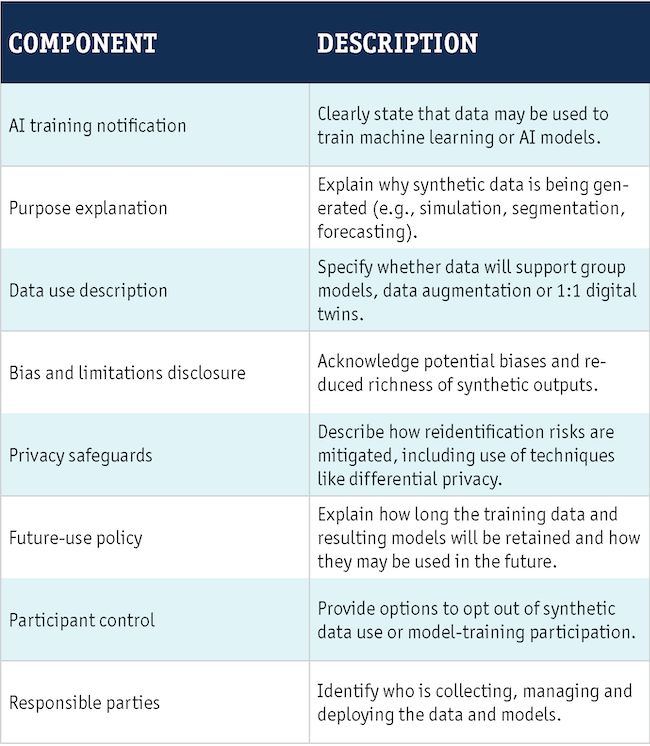
This level of specificity demonstrates respect for participants’ data sovereignty and promotes trust in synthetic data applications.
Regulation, reputation and risk
If acting in an ethical manner isn’t enough of a motivator on its own, consider this: Regulatory bodies are paying attention.
- The Federal Trade Commission has taken action against companies that trained models without explicit consent, even if synthetic outputs were used.
- Under GDPR, even pseudonymized data used for AI training may trigger data protection obligations if reidentification is possible.
- The AI CONSENT Act, introduced in the U.S., seeks to mandate clear consent for AI training using consumer data.
Beyond compliance, reputation is at stake. Brands and research providers who are caught misusing participant data – or downplaying synthetic data risks – may suffer credibility losses with clients, regulators and the public. As synthetic data applications accelerate, ethical leadership becomes a brand asset in its own right.
A blueprint for ongoing ethical engagement
One of the most promising frameworks for addressing the limitations of traditional informed consent is the concept of dynamic consent. Unlike static consent where participants grant one-time approval for data use, dynamic consent is a technology-enabled, participant-centered model that fosters ongoing interaction, transparency and control.
This model is particularly well-suited to synthetic data and digital-twin applications, where data may be reused, updated or reinterpreted by evolving AI systems. Dynamic consent transforms the participant’s role from passive contributor to active stakeholder.
At the heart of dynamic consent is a secure digital platform, accessible via web or mobile app, through which participants can:
- Review and manage their consent preferences in real time: Participants can specify which types of research or data use they agree to and change these preferences whenever they choose.
- Receive updates on how their data is being used: If their data is involved in training a new model, used in a secondary analysis or transferred to a partner organization, participants are notified and can choose to continue or withdraw their involvement.
- Opt in or out of specific studies: Rather than blanket consent for any future use, participants receive invitations to new research initiatives and can consent (or not) on a case-by-case basis.
- Access study results or summaries: In a two-way communication model, researchers can share insights, results or even model outputs with participants – enhancing trust, transparency and participant engagement.
- Track and audit their own data use: A log of consent history, changes and interactions provides both participants and organizations with a clear record of data governance, supporting regulatory compliance (e.g., GDPR, HIPAA).
Synthetic data systems, particularly those trained on real behavioral data, are not static entities. They evolve. They update. They are deployed in new ways and sometimes reused for purposes unimagined at the time of original data collection. This reality demands a consent model that is as dynamic as the systems it governs.
Dynamic consent ensures that participants have agency not just in the moment of initial data collection but across the entire lifecycle of data use and synthetic model evolution. It allows researchers to ethically harness the benefits of synthetic data while preserving the core principle that participants must understand and agree to how their data is used.
Let’s not lose the plot
Market research is, at its core, a human endeavor. It’s about understanding people – their needs, motivations, frustrations and desires. When we shift toward AI-driven modeling and synthetic simulation, we risk forgetting that the intelligence we simulate is borrowed. Every synthetic model starts with a real person who chose to share their thoughts with us.
We owe them transparency. We owe them agency. And we owe them more than a checkbox on a form that barely scratches the surface of what’s at stake.
Informed consent isn’t just a compliance requirement; it’s a moral contract. If we’re going to extract value from people’s data to build machines that think like them, we must ensure that consent is informed, continuous and worthy of their trust.